Great AWS cloud consulting engagements do not start with tools, they start with outcomes. If you are a CTO, Head of Engineering, or platform team lead evaluating partners, this guide shows what great looks like in practice, how to measure it, and the artefacts you should expect at every stage.
Define success upfront, measure it continuously
Strong engagements anchor on business outcomes, then translate them into a small, auditable scorecard. The exact targets vary by organisation, but the categories rarely change.
| Outcome | How to measure | Typical baseline example | Target after 60–90 days | Data source |
|---|---|---|---|---|
| Delivery speed | Deployment frequency, lead time for changes (DORA) | Weekly deploys, multi‑day lead time | Daily or multiple daily deploys, hours lead time | CI/CD, Git, change calendar |
| Reliability | SLO compliance, p95 or p99 latency, error budget burn, MTTR | No SLOs, reactive firefighting | SLOs defined and met, MTTR reduced by 20–40 percent | APM, logs, incident tool |
| Cost efficiency | Cost per environment or per request, allocation coverage, idle spend | Partial tagging, unknown unit costs | 90 percent+ cost allocation, 10–30 percent waste eliminated | CUR, cost tool, tagging |
| Security posture | High‑risk findings open, patch latency, identity hygiene | Ad hoc reviews | Vulnerability MTTR reduced, CIS benchmarks enforced | Security Hub, IAM Access Analyzer |
| Team capability | On‑call confidence, platform self‑service adoption | Platform bottlenecks | Self‑service golden paths, documented runbooks and handover | Retros, platform telemetry |
For credibility and alignment, reference recognised frameworks during planning and reviews, for example the AWS Well‑Architected Framework, the FinOps Framework, and DORA metrics. These are widely adopted and publicly documented by AWS and industry bodies.
- AWS Well‑Architected Framework, pillars and reviews: AWS Well‑Architected Framework
- Cloud cost management practices: FinOps Framework
- Software delivery performance research and metrics: DORA
The anatomy of a great AWS cloud consulting engagement
Great engagements are structured, time‑boxed, transparent, and automation‑first. Below is a proven pattern that scales from fast‑moving SaaS to regulated enterprises.
1. Align on outcomes and constraints
- Stakeholder workshop to clarify business goals, regulatory context, budget and timeline.
- Define a minimal KPI scorecard and agree what good looks like.
- Identify one or two high‑value use cases for the first 90 days.
2. Baseline with a Well‑Architected lens
- Run a focused review across the five pillars, map risks to severity and effort.
- Inventory accounts, networks, identities, CI/CD and monitoring. Confirm data flows and data classification.
3. Blueprint the target state and plan
- Design a secure landing zone, identity and access model, network topology, and guardrails.
- Decide build versus buy for platform components, for example EKS versus ECS, managed RDS versus self‑managed.
- Produce a roadmap with quick wins in the first 30 days.
4. Quick wins, fast feedback
- Implement low‑risk, high‑impact changes, for example gp3 migration for EBS, S3 Intelligent‑Tiering, rightsizing, and tagging fixes.
- Stabilise noisy on‑call with pragmatic observability improvements and SLOs for critical services.
5. Build with code, not clicks
- Stand up or remediate the landing zone via Infrastructure as Code, for example Terraform, CloudFormation.
- Establish golden paths and a repeatable CI/CD template, for example GitHub Actions or CodePipeline, with automated tests and policy gates.
- Integrate continuous security, for example image scanning, SBOMs, IAM least privilege, and WAF.
6. Migrate in waves, prove with tests
- Pick a pilot service, execute blue‑green or canary deployments, verify with synthetic checks and load tests.
- Scale to additional services, then data stores, with rollbacks rehearsed in advance.
7. Operate, govern and optimise
- Turn on showback, budgets and alerts. Track unit economics, for example cost per request or per tenant.
- Establish weekly operations rituals, review SLOs, error budgets and cost trends.
8. Enablement and handover
- Deliver runbooks, diagrams, and a knowledge base.
- Train teams on platform use, on‑call, incident response, and cost hygiene. Transition to steady‑state support if required.

What you should expect to receive, not just hear
| Deliverable | What good looks like |
|---|---|
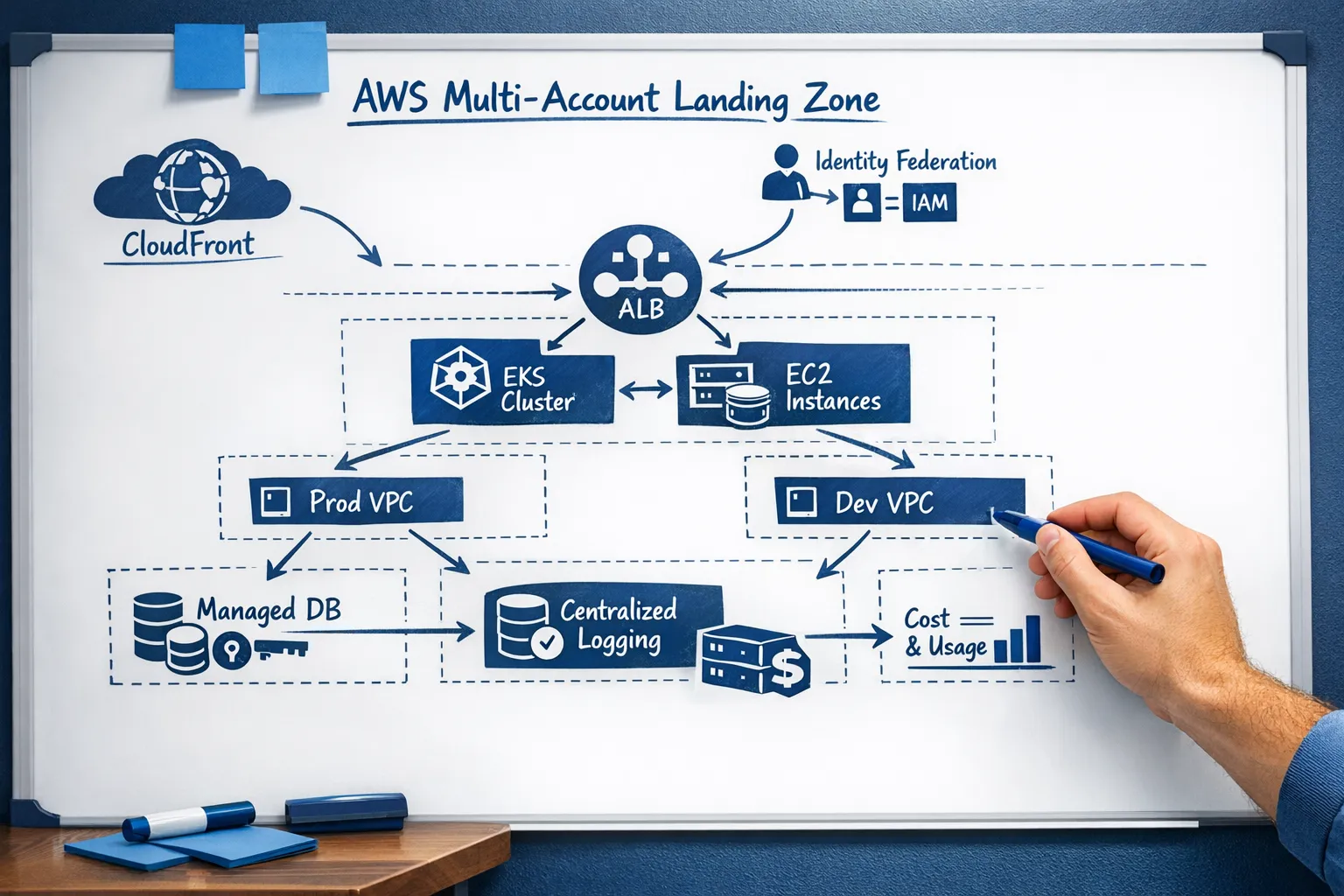
| Target architecture and landing zone design | Multi‑account model using AWS Organisations, identity federation, network segmentation, baseline security controls, documented in diagrams and code |
| IaC repositories | Versioned Terraform or CloudFormation modules, code reviews, CI checks, no manual console drift |
| CI/CD templates | Standardised pipeline with build, test, scan, deploy stages, environment promotions, automated rollback |
| Observability stack | Service dashboards, SLOs, golden signals, alert routing to Slack or PagerDuty, runbooks linked |
| Security baseline | CIS‑aligned benchmarks applied, GuardDuty and Security Hub enabled, KMS encryption at rest, WAF for internet‑facing |
| Cost programme | Complete tagging policy, CUR enabled, budgets and anomaly alerts, Savings Plans or RIs modelled and approved |
| Migration playbooks | Cutover plans, backout steps, synthetic probes and load tests, success criteria defined |
| Documentation and training | Platform handbook, architecture runbooks, onboarding guides, recorded walkthroughs |
If any of the above are missing, ask when they will land and how they will be tested.
Security and compliance by default
Security should be designed in, not scanned in late. Expect identity federation with least privilege IAM roles, key management with KMS, private networking by default, encrypted storage, logging at ingress and egress, and continuous vulnerability management. In regulated environments, the operating model and audit trail matter as much as the tech. If you are operating under ISO 27001, SOC 2, PCI DSS or healthcare regulations, insist that the controls map to your policy and that evidence collection is automated where possible.
For a practical checklist to benchmark your controls, see our Cloud Security Checklist for 2025 that covers governance, identity, network, data protection, supply chain and resilience.
- Cloud security checklist by Tasrie IT Services: Cloud Computing Security Checklist for 2025
FinOps is a first‑class workstream, not an afterthought
Great AWS consulting bakes cost governance into day one.
- Enable Cost and Usage Reports and tagging early, aim for 90 percent+ allocation coverage.
- Eliminate quick waste, for example idle EBS volumes, unattached IPs, oversized instances.
- Model and validate Savings Plans or Reserved Instances for steady workloads.
- Optimise storage classes, for example S3 Intelligent‑Tiering, and EBS gp3 migrations where appropriate.
- Establish monthly cost reviews tied to business value, not only totals.
For a pragmatic framework that UK organisations use to prove savings, explore our Measure, Optimise, Govern guide: AWS Cloud Cost Optimisation: A Practical Guide
Performance and scale, proven in real workloads
The best architectures balance simplicity with headroom. For latency‑sensitive workloads, for example trading, gaming or real‑time analytics, customer expectations are set by tools that feel instant. As a reference for speed‑first UX in financial markets, review this low‑latency options trading interface. When your application teams target similar user expectations, the cloud platform must deliver efficient networking, autoscaling and observability so front‑end speed is matched by back‑end reliability.
On AWS, common performance patterns include regional and Availability Zone selection for user proximity, managed databases like RDS or Aurora with read replicas, autoscaling groups or EKS with HPA and Cluster Autoscaler, and pragmatic caching layers like CloudFront and Redis. Benchmarks should be run continuously, not only pre‑launch.
Red flags that signal a weak engagement
- Tool‑first proposals that skip discovery and outcomes.
- No Infrastructure as Code, or code that cannot be reproduced end to end.
- No SLOs, no synthetic checks, alerts wired to email rather than incident tooling.
- Cost work delayed until after migration, missing tagging and allocation.
- Security positioned as a later phase, not continuous.
- Vague deliverables, no acceptance criteria, no knowledge transfer plan.
What this looks like with Tasrie IT Services
Our approach is outcome‑driven and senior‑engineer led. Recent stories illustrate the breadth of results across cost, reliability and speed:
- 30 percent monthly EKS cost reduction using spot strategy, resilient disruption handling and guardrails: 30% Cost Reduction in AWS EKS Monthly Bill Through Spot Instance Optimization
- A mid‑market SaaS company avoided a failed DIY migration, completing a consultant‑led Kubernetes move with zero downtime and faster deployments: How a Mid‑Market SaaS Company Saved $253K on Kubernetes Migration
- Eliminated an unnecessary enterprise API gateway during observability work, saving about 100,000 USD while improving performance: USD 100K Saved by Replacing Enterprise API Gateway
- Modernised a healthcare organisation onto AWS with auto‑scaling, multi‑region DR and fewer security incidents: Cloud Migration for Enhanced Financial Efficiency and Cybersecurity in Healthcare
If resilience is your priority, this practical guide outlines patterns and a 30, 60, 90 day plan: Designing Resilient Cloud Infrastructure on AWS
A realistic 90‑day plan, and the minimum shippable outputs
| Week | Focus | Minimum outputs |
|---|---|---|
| 1–2 | Discovery and baseline | Outcomes scorecard, Well‑Architected risk map, account and asset inventory |
| 3–4 | Blueprint and quick wins | Target architecture, landing zone plan, top five cost and reliability fixes applied |
| 5–6 | IaC and CI/CD foundations | Reproducible landing zone with IaC, CI/CD template with security scans, policy gates |
| 7–8 | Observability and security baseline | Service dashboards and SLOs, alert routing, GuardDuty and Security Hub enabled |
| 9–10 | Pilot migration and validation | Pilot service deployed via blue‑green or canary, synthetic probes, load test results |
| 11–12 | Optimisation and handover | Savings plan model, runbooks, platform handbook, recorded training and next‑wave plan |
Questions to ask any AWS cloud consulting partner
- How will you measure success weekly and what data sources will you use?
- What are the first five quick wins you plan to deliver in 30 days, and how will we validate them?
- Can you show the landing zone and pipelines as code, end to end, in a fresh account?
- How will you implement SLOs and wire incidents to our existing tools?
- What is your tagging and allocation plan so finance can track cost per product or tenant?
- How do you handle knowledge transfer, handover, and support after go‑live?
- Which risks did you uncover in discovery, and how are they mitigated in the plan?
Frequently asked questions
How long should an AWS cloud consulting engagement take before we see value? Tangible improvements usually land in the first 30 days, for example rightsizing, tagging and initial SLOs. Meaningful platform foundations, a pilot migration and handover materials typically fit into a 60–90 day window for a well‑scoped project.
What AWS services are common in modern reference architectures? Most teams combine VPC, IAM, KMS, CloudTrail, Config, GuardDuty, Security Hub, EC2 or EKS, RDS or Aurora, S3, CloudFront, Load Balancers and CloudWatch. The exact mix depends on workloads, regulatory needs and team skills.
Do we need Kubernetes to be cloud native on AWS? Not always. Many teams succeed with ECS or serverless first. If you already run containers across clouds, EKS can provide portability and ecosystem benefits. The key is platform discipline, IaC and strong CI/CD, not a specific scheduler.
How do we control cloud costs during a migration? Start with tagging and allocation coverage, set budgets and anomalies, then sequence quick wins like storage optimisation and rightsizing. Model Savings Plans once steady‑state usage is evident. We outline a proven approach in our cost optimisation guide.
What proof should we ask for before committing? Ask to see reproducible landing zone code, pipeline templates, and examples of SLO dashboards. Request case studies with measurable outcomes and references you can speak to.
Ready to see what a great AWS engagement looks like in your context?
Whether you want to accelerate a migration, stabilise operations, or reduce spend without sacrificing performance, our senior consultants can help you design the plan, deliver the quick wins, and leave your team stronger.
Talk to Tasrie IT Services about your goals and constraints, and we will share a pragmatic path you can validate quickly. Get in touch.