High availability is not a luxury on AWS, it is a design choice that you can make explicit from day zero. Resilient cloud infrastructure anticipates failure, contains blast radius, and recovers gracefully while protecting data and cost efficiency. This guide distils practical, field‑tested patterns you can apply on AWS to keep services online and customers happy, even when components fail.
What resilience means on AWS
Resilience covers the ability to withstand faults and recover quickly without breaching user expectations or compliance obligations. You should define three targets up front and let them drive design and budgets:
- Service Level Objectives, the customer promise for availability and latency
- Recovery Time Objective, how long you can be down before you must be back
- Recovery Point Objective, how much data you can afford to lose
Translate these into concrete engineering guardrails: design for multi‑AZ by default, minimise shared fate, prefer stateless services, automate recovery, and continuously test what you built.
A resilient reference architecture on AWS
At a high level, a robust AWS foundation looks like this.
- Multi‑account landing zone with guardrails for isolation and least privilege, separate production from non‑production
- VPC per environment spread across at least two, ideally three Availability Zones, with public, private application, and private data subnets per AZ
- One NAT Gateway per AZ, route private subnets to the NAT in the same AZ to avoid cross‑AZ dependencies
- VPC endpoints for S3, DynamoDB and other critical services, this removes internet dependencies for control and data paths
- Global ingress using CloudFront, AWS WAF and Shield, application ingress through ALB or NLB as appropriate
- Compute on Auto Scaling groups, EKS or ECS, size for N minus one capacity and add disruption budgets
- Managed data services with built‑in failover and cross‑region replication options where required
- Observability across logs, metrics and traces, with actionable alerting and runbooks
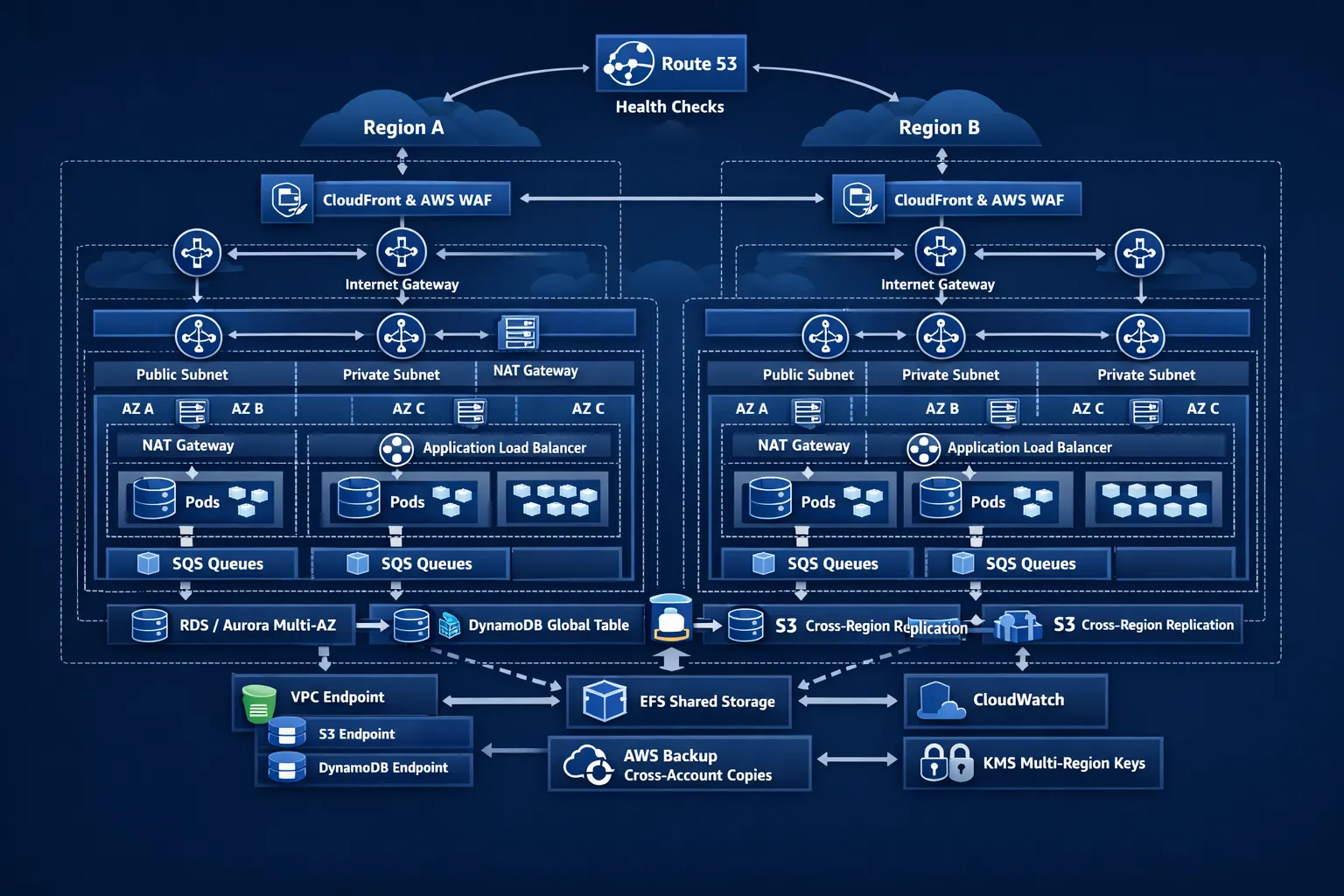
Ingress and traffic management
- Use CloudFront for global edge caching and DDoS absorption, pair it with AWS WAF for rules and managed protections
- Choose ALB for HTTP and gRPC, NLB for TCP and ultra‑low latency
- Configure Route 53 health checks with failover, latency‑based or weighted routing, for multi‑region strategies consider AWS Global Accelerator for faster, deterministic failover
Compute layer
- EC2 with Auto Scaling: set capacity‑rebalancing, use a mix of On‑Demand, Reserved or Savings Plans, and Spot with the capacity‑optimised allocation policy
- Kubernetes on EKS: enforce PodDisruptionBudgets, topology spread constraints, and readiness probes, run cluster autoscaler, and drain nodes during maintenance
- ECS on Fargate or EC2: multiple capacity providers for AZ diversity and Spot fallbacks
Decoupling and backpressure
- SQS for durable queues, SNS for pub or sub broadcasts, EventBridge for integration across domains, these services smooth spikes and isolate failures
- Step Functions for orchestrating retries with exponential backoff and compensation logic
Data layer patterns
Choose the storage that matches your consistency and recovery needs.
| Data service | HA within region | Cross‑region option | Notes |
|---|---|---|---|
| Amazon RDS Multi‑AZ | Synchronous failover in the same region | Read replicas or automated cross‑region snapshots | Good default for transactional databases, plan application DNS changes for regional failover |
| Amazon Aurora | Multi‑AZ with fast failover | Aurora Global Database for low‑latency reads and regional disaster recovery | High availability, fast recovery and global read scaling |
| DynamoDB | Regional service with multi‑AZ durability | Global Tables for multi‑region multi‑writer | Excellent for near zero RPO across regions with eventual consistency between regions |
| Amazon S3 | Eleven nines durability across multiple AZs | Cross‑Region Replication and Multi‑Region Access Points | Class lifecycle to Glacier for archive, use Object Lock when compliance needs WORM |
| Amazon EFS | Regional, multi‑AZ file system | Replicate with AWS Backup, application‑level sync | Prefer EFS Standard for resilience, One Zone trades cost for availability |
| ElastiCache for Redis | Multi‑AZ with automatic failover | Cross‑region replicas or application‑level dual writes | Enable Redis cluster mode for scale and shard‑level resilience |
Security is integral to resilience. Use KMS for encryption at rest, customer managed keys where required, and multi‑region keys for cross‑region recovery scenarios. Store secrets in Secrets Manager, not in environment variables or code.
Disaster recovery strategies and trade‑offs
The right DR approach balances RTO and RPO with budget and complexity. Map workloads by criticality and pick a strategy per workload, not one size for all.
| Strategy | Architecture summary | Typical RTO | Typical RPO | Relative cost | Common use |
|---|---|---|---|---|---|
| Backup and restore | Regular snapshots and backups to S3, restore on demand in target region | Hours to days | Hours | Low | Internal tools, non‑customer facing systems |
| Pilot light | Minimal core services always running in DR region, data replicated continuously | Hours | Minutes to hours | Medium | Business‑critical apps that can tolerate some downtime |
| Warm standby | Scaled down but functional stack in DR region, ready to scale up | 30 to 60 minutes | Minutes | Medium to high | Customer‑facing services with revenue impact |
| Active‑active multi‑region | Traffic served from multiple regions, data replicated across regions | Seconds to minutes | Seconds to minutes | High | Always‑on, global applications with strict SLOs |
Automate DR with infrastructure as code and runbooks. Use AWS Backup for central policy management and cross‑account, cross‑region copies. For complex multi‑region failover, consider AWS Application Recovery Controller for routing controls and readiness checks.
Observability, testing and operations
Visibility is how you prove resilience works in reality.
- Metrics and logs: standardise on CloudWatch metrics and logs, enrich with structured fields, forward to a long‑term store if you need extended retention
- Traces: instrument services with OpenTelemetry and view in X‑Ray or your chosen APM tool
- SLOs and error budgets: track availability and latency against budgets, prioritise reliability work when you consume the budget too fast
- Alerting: ensure alerts map to customer impact, include runbook links, and avoid noisy, non‑actionable signals
- Game days and chaos: use AWS Fault Injection Simulator to validate failover, AZ outages, and dependency breaks, test backups by restoring and performing application‑level verification
For a deeper dive into building an observability stack that supports resilience, see our guide on Observability and Effective Monitoring at Tasrie IT Services.
Security and compliance as a resilience guarantee
Breaches and misconfigurations are outages by another name. Bake security into the design.
- Identity: least‑privilege IAM roles, short‑lived credentials via SSO, isolated production accounts
- Network: private subnets by default, security groups as primary controls, VPC endpoints for SaaS integrations where available
- Perimeter: AWS WAF with managed rule sets, Shield Advanced for DDoS protection on critical zones, CloudFront as the first touchpoint
- Data protection: KMS encryption, Secrets Manager rotation, S3 Block Public Access and bucket policies, database activity streams where mandated
- Governance: Security Hub, GuardDuty, Config rules and detective controls to catch drift early
Cost‑aware resilience
Highly available does not mean highly expensive. Thoughtful design avoids waste.
- Keep NAT Gateway per AZ for reliability, reduce egress by using VPC endpoints and placing dependencies in the same AZ to limit cross‑AZ data transfer
- Mix purchase options, commit steady state to Savings Plans or RIs, burst with Spot using capacity‑optimised strategies
- Right‑size instance families and storage classes, adopt gp3 for EBS, use S3 lifecycle to tier cold data
- Cache intelligently with CloudFront, Redis and application caching to cut database load
If you want a structured playbook to bring spend under control while you increase reliability, our AWS cloud cost optimisation guide outlines a pragmatic 90‑day approach that works.
A pragmatic 30, 60, 90 day roadmap
Day 0 to 30, foundations
- Define SLOs, RTOs, RPOs per service, classify workloads by criticality
- Land multi‑account structure, identity, logging and baseline guardrails
- Build a three‑AZ VPC pattern with one NAT per AZ, VPC endpoints for S3 and DynamoDB
- Stand up ingress, CloudFront, WAF and ALB, deploy a sample workload and baseline dashboards
Day 31 to 60, hardening
- Migrate stateful services to Multi‑AZ options, plan cross‑region replication where required
- Introduce SQS or EventBridge to decouple chatty dependencies
- Add automated backups with cross‑region copies, test restores
- Implement cluster autoscaler and disruption budgets on EKS or ECS capacity providers
Day 61 to 90, recovery and optimisation
- Choose DR strategies per workload, automate failover and rehearse runbooks
- Roll out AWS Fault Injection Simulator scenarios, remediate weak points n- Tune autoscaling policies, adopt purchase commitments and Spot where safe
- Finalise dashboards, alerts, and on‑call playbooks mapped to business impact
Sector example, healthcare
Healthcare providers depend on reliable digital services for bookings, records and clinical coordination. Consider how fragile an appointment system would be if a regional outage stopped patient check‑ins. A resilient design, for example global edge caching, multi‑AZ application clusters and cross‑region replicated data stores, maintains service continuity and protects patient trust. Even a focused, specialised provider such as a specialised ENT clinic in Dubai benefits from resilient infrastructure because it keeps scheduling, test results and follow‑up messaging available when patients need them most.
Common failure modes to design out
- Single NAT Gateway serving all AZs, introduces a hidden single point of failure and cross‑AZ costs
- Stateless front ends paired with a single‑AZ database, front ends survive but the app is still down
- Hard coded IPs or regional endpoints in application configs, makes failover brittle
- Orphaned dependencies on the public internet, a SaaS or third party outage cascades into yours
- Manual recovery steps, people are not pagers, make recovery push button
Putting it together
Designing resilient cloud infrastructure on AWS is a discipline, not a product. Start with the customer promise, choose the minimum DR approach that meets it, and automate everything from deployment to failover and verification. Measure the real user experience and prove recovery regularly.
Tasrie IT Services helps teams architect and operate resilient platforms with DevOps, cloud native and automation expertise. We build outcomes‑driven roadmaps, implement the right AWS building blocks, and leave your teams with the tooling, runbooks and confidence to run at scale.
If you want help pressure‑testing your current design or building a resilient AWS foundation the right way, talk to our specialists today.
Further reading from Tasrie IT Services
- Observability, Effective Monitoring
- AWS Cloud Cost Optimisation, A Practical Guide