Most teams don’t fail at cloud because they chose the “wrong” provider. They fail because they treat infrastructure cloud services as a one-off migration project, instead of an operating system for delivery, security, and cost control.
This quick start guide is for CTOs, engineering managers, platform teams, and IT leaders who want a practical, vendor-neutral way to get a reliable cloud foundation in place, fast, without over-engineering.
What “infrastructure cloud services” actually include
“Infrastructure cloud services” is often used as a catch-all term, but it helps to be precise. At its core, it’s the set of cloud capabilities that let you run workloads safely and repeatably: compute, storage, networking, identity, security controls, observability, and the automation that ties everything together.
A useful framing is the NIST definition of cloud computing, which emphasises on-demand self-service, broad network access, resource pooling, rapid elasticity, and measured service. That last part, “measured”, is why cost and governance must be designed in from day one.
Cloud infrastructure, mapped to ownership
Even with “fully managed” services, cloud is never “set and forget”. You need clear ownership across platform, security, and delivery.
| Capability area | What it covers | Typical primary owner |
|---|---|---|
| Identity and access | SSO, least privilege, roles, access reviews, break-glass | Security + Platform |
| Networking | VPC/VNet design, routing, private connectivity, DNS, egress controls | Platform |
| Compute | VMs, managed Kubernetes, serverless runtime choices | Platform + Product teams |
| Data foundations | Object storage, managed databases, encryption, backups | Platform + Data teams |
| Observability | Metrics, logs, traces, alerting, SLOs | SRE/Platform |
| Automation | IaC, CI/CD, GitOps, policy-as-code | Platform |
| Governance and cost | Tagging, budgets, unit cost tracking, guardrails | Platform + FinOps |
If you only take one thing from this section: infrastructure cloud services are not just “servers in the cloud”. They are your production controls.
Quick-start decision 1: choose your baseline model (IaaS, PaaS, or serverless)
A fast cloud start is about picking the simplest model that still meets your constraints (security, latency, compliance, scalability, team capability).
Here’s a pragmatic decision matrix you can use early.
| Model | Best when | Watch-outs |
|---|---|---|
| IaaS (VMs + managed services) | You have legacy workloads, custom networking needs, or you want maximum control | Operational burden creeps in quickly without automation |
| Managed Kubernetes | You need portability, standardised deployment, and lots of microservices | Requires maturity in security, observability, and cluster operations |
| Serverless (functions + managed event services) | You want speed and elasticity for event-driven and spiky workloads | Debugging, cold starts, and governance need deliberate design |
If you are unsure, default to “managed services first” (managed databases, managed load balancers, managed identity) while you build operational muscle.
Quick-start decision 2: region, data residency, and regulatory constraints
Don’t wait until after you’ve built your platform to ask “Where can we run this?” Establish these constraints upfront:
- Data residency (where data must live, where backups can be stored, where logs can be processed)
- Encryption and key management expectations (provider-managed keys vs customer-managed keys)
- Audit evidence requirements (centralised logs, retention policies, access logging)
- Third-party risk (which managed services are allowed, and which are restricted)
For many organisations, this becomes a simple “workload placement policy” that decides what can run in public cloud, what must stay private, and what can be hybrid.
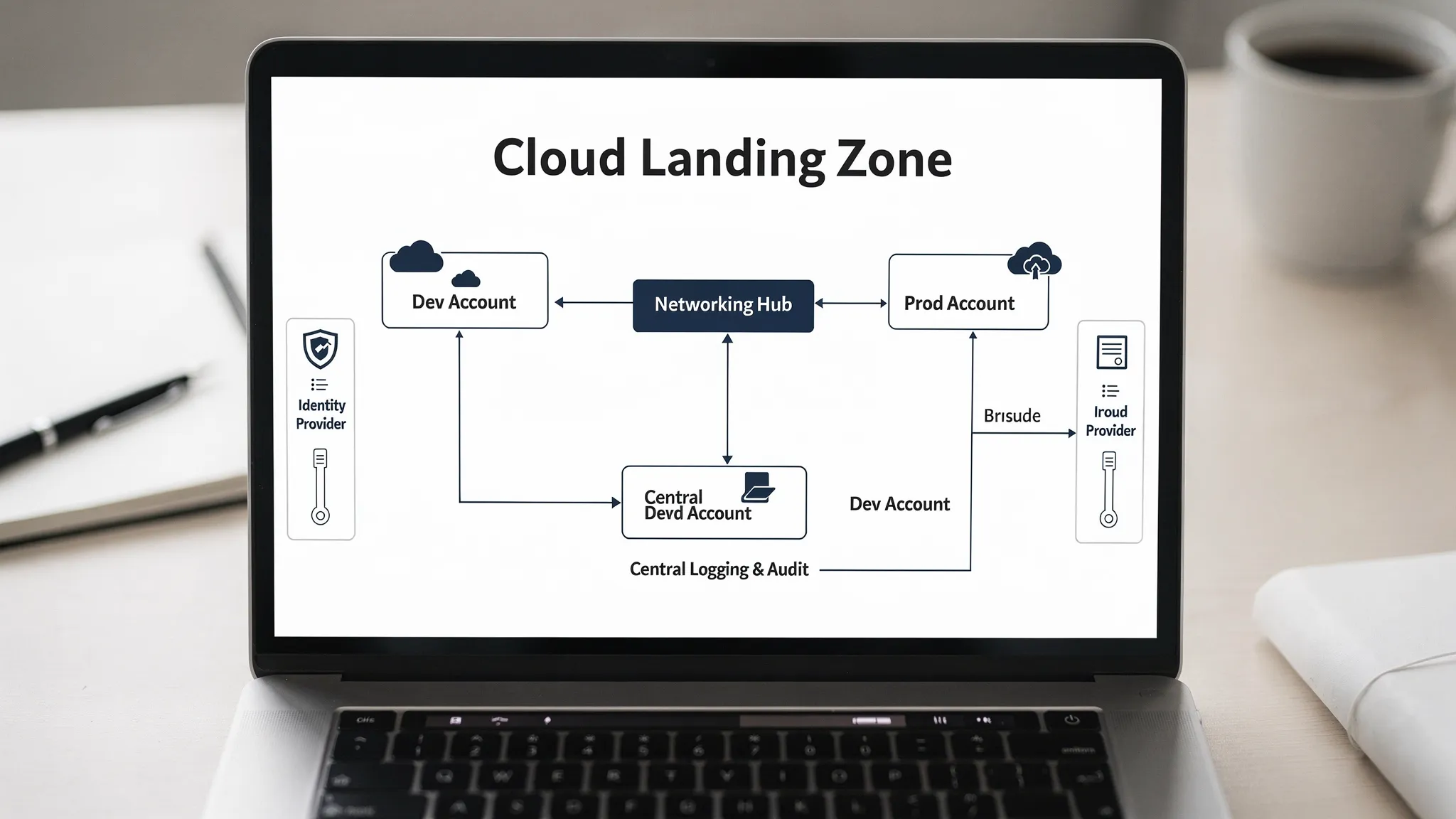
Build a minimum viable landing zone (before you migrate anything important)
A landing zone is the secure, repeatable foundation of your cloud environment. It’s how you prevent “random cloud” (ad-hoc accounts, inconsistent networks, unclear logging) from becoming your default.
Minimum landing zone blueprint
A quick-start landing zone usually includes:
- Separate environments (at least dev and prod, ideally also staging)
- Centralised identity (SSO and role-based access)
- A standard network pattern (segmented subnets, routing rules, egress control)
- Central logging and audit trails
- Baseline security guardrails (policy enforcement, vulnerability scanning hooks)
- Budgeting and tagging standards
Guardrails first, then speed
A common anti-pattern is trying to “move fast” by skipping guardrails, then later discovering:
- Teams can’t trace changes because too much is manual
- Security can’t prove who accessed what
- Costs grow unpredictably because nothing is tagged and no budgets exist
A well-designed landing zone prevents those problems while still enabling fast delivery.
If you want a detailed reference for how mature organisations structure these controls, the AWS Well-Architected Framework is a solid vendor example, even if you run multi-cloud.
Make Infrastructure as Code your default change mechanism
If your cloud foundation is created in click-ops, it will drift. If it’s created in Infrastructure as Code (IaC), it can be reviewed, tested, and reproduced.
IaC quick-start rules that prevent drift
- Everything is code: networks, IAM, clusters, databases, logging sinks, policies.
- One repo structure you can explain: keep it boring and consistent.
- Remote state with locking: reduce “two engineers applied different plans” incidents.
- Mandatory reviews: treat infrastructure changes like application changes.
Tasrie IT Services has several deep-dive Terraform guides (for example, how to set up an S3-backed Terraform state) that can help teams standardise quickly, but the main goal is bigger than Terraform: it’s adopting a repeatable change system.
A simple delivery flow for infrastructure
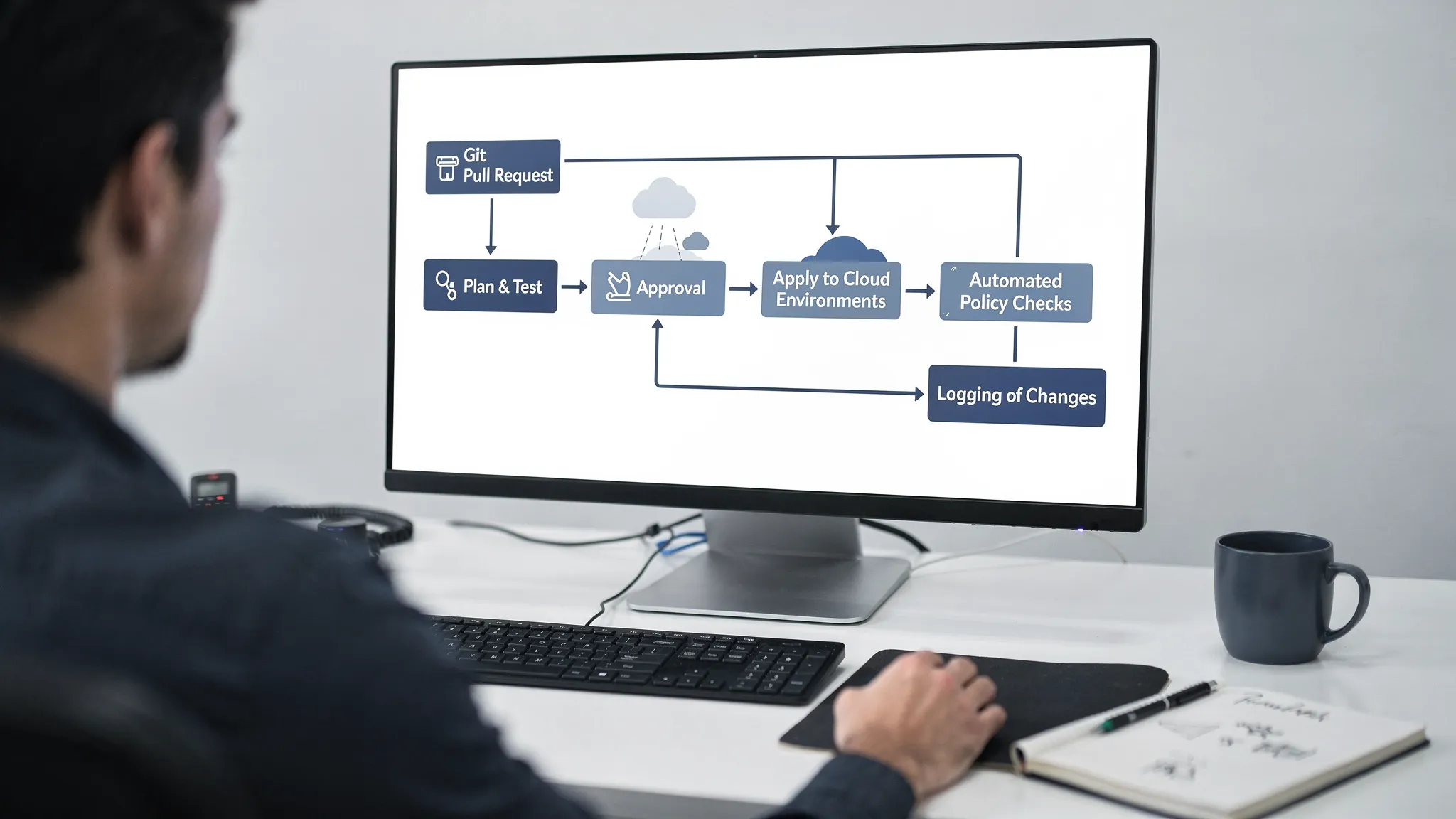
A lightweight but effective pattern is:
- Pull request runs: formatting, linting, static security checks,
plan - Human approval (and optionally change window rules for production)
- Apply with auditable identity (no shared credentials)
- Automatic drift detection and alerting
Build a “cloud service catalogue” instead of letting every team reinvent infrastructure
Fast infrastructure cloud services are not about giving everyone full freedom. They’re about giving teams safe choices.
Start with a small, opinionated catalogue of approved building blocks.
| Catalogue item | Standard default | Why it matters |
|---|---|---|
| Compute runtime | VM, managed Kubernetes, serverless | Reduces tool sprawl and security variance |
| Database | Managed relational, managed NoSQL | Improves reliability and reduces maintenance |
| Secrets | Managed secrets store | Prevents secrets in repos and environment variables |
| Logging/metrics/tracing | Standard collectors and backends | Enables consistent incident response |
| Networking pattern | Shared hub + segmented spokes | Avoids uncontrolled connectivity growth |
This approach also makes onboarding easier: new services get a paved road, not a blank page.
Observability: the fastest way to reduce downtime is to design for detection
Cloud gives you elasticity, but it also increases system complexity. Observability is how you maintain control.
A practical place to start is the three pillars:
- Metrics (what is happening)
- Logs (why it happened)
- Traces (where it happened across services)
Open standards like OpenTelemetry can reduce vendor lock-in and help you standardise instrumentation across teams.
The minimum “production visibility” scorecard
| Signal | What to track first | Why |
|---|---|---|
| Availability | Uptime for user-facing endpoints, error rate | Keeps reliability user-centric |
| Latency | p95 and p99 latency on key API paths | Captures real user pain |
| Saturation | CPU, memory, queue depth, DB connections | Predicts incidents before they happen |
| Deployment health | Change failure rate, rollback frequency | Shows whether delivery is safe |
If you operate customer-facing automation products, you’ll also want strong rate limiting, observability, and security around external integrations. A tool like an autonomous AI SDR for LinkedIn outreach is a good example of a workload where reliable infrastructure, careful scaling, and audit-friendly operations directly affect business outcomes.
Cost control is part of infrastructure (not a monthly finance report)
The cloud’s biggest advantage, pay-as-you-go, becomes a disadvantage if you don’t create feedback loops.
Quick-start cost controls that actually work:
- Tagging standard for cost allocation (owner, environment, service)
- Budgets and alerts for each environment and high-risk service
- Rightsizing reviews tied to utilisation (not opinion)
- Autoscaling policies that include safe limits (to prevent runaway scale)
If you want a deeper operational approach, you can model this as “FinOps guardrails”: teams can scale, but they must be able to explain unit cost.
A 14-day quick start plan you can execute
This plan is designed to get a safe baseline in place quickly, without pretending you can finish a full cloud programme in two weeks.
| Timeline | Focus | Deliverables you should insist on |
|---|---|---|
| Days 1 to 2 | Discovery and constraints | Workload inventory snapshot, compliance constraints, target architecture sketch |
| Days 3 to 5 | Landing zone baseline | Account/subscription structure, IAM/SSO integration, central audit logging enabled |
| Days 6 to 8 | Networking and security defaults | Standard VPC/VNet pattern, segmentation, baseline policies, secrets approach |
| Days 9 to 11 | IaC and delivery foundations | IaC repo structure, remote state, PR checks, environment promotion rules |
| Days 12 to 14 | Observability and cost guardrails | Minimum dashboards, alerting routes, budget alerts, tagging enforcement |
At the end of two weeks, you should be able to answer:
- Can we provision infrastructure repeatedly from scratch?
- Can we prove who changed what and when?
- Can we detect production issues quickly and route alerts to the right owners?
- Can we attribute costs to teams and environments?
If the answer is “yes”, you’re ready to migrate higher-stakes workloads.
Common failure modes (and how to avoid them early)
The fastest way to improve outcomes is to avoid mistakes that create long-term operational debt.
- Manual changes in production: fix with IaC-only policies and change audits.
- Flat networks and over-trusting connectivity: fix with segmentation, private endpoints, and explicit traffic policies.
- Over-permissive IAM: fix with least privilege roles, short-lived credentials, and access reviews.
- Backups and DR treated as a later project: fix with backup defaults, retention rules, and restore tests.
- Observability added after incidents start: fix with baseline dashboards and SLO-driven alerting from day one.
- Cost visibility missing: fix with tagging enforcement, budgets, and unit-cost thinking.
Where Tasrie IT Services can help (without locking you into a “big bang” programme)
If you want to accelerate infrastructure cloud services without risking production stability, the highest-leverage support usually looks like:
- A short assessment to baseline your cloud readiness, risks, and bottlenecks
- A landing zone implementation (or remediation of an existing one)
- IaC and CI/CD standardisation to remove manual drift
- Observability and on-call readiness to reduce MTTR
- Cost optimisation tied to measurable outcomes
Tasrie IT Services has delivered measurable cloud outcomes across migration, Kubernetes platforms, monitoring, and cost optimisation. For example, their AWS migration work has documented cost reduction and availability improvements in real client environments (see the finance migration story on their site: Migrating Finance Applications to AWS Cloud for 30% Cost Reduction).
If you want to discuss a quick-start landing zone, IaC foundations, or a pragmatic path to production-grade cloud operations, you can start at Tasrie IT Services and align the engagement around outcomes: faster delivery, improved reliability, and controlled cloud spend.