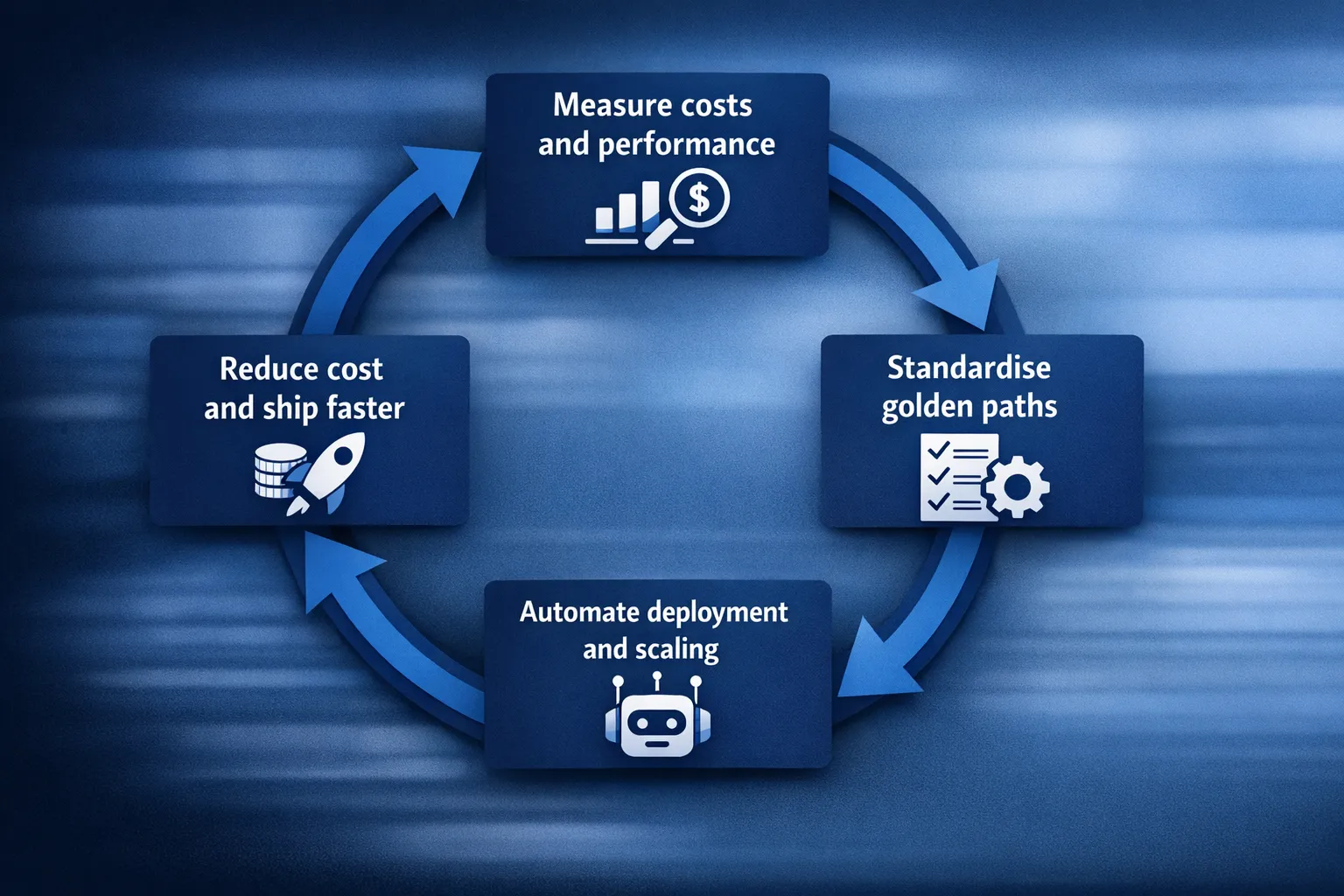
Most cloud programmes fail for one of two reasons: they optimise for cost and slow delivery to a crawl, or they optimise for speed and wake up six months later to an alarming bill (and a fragile platform). In 2025, the winning approach is neither austerity nor “move fast and fix later”. It’s an outcomes-led cloud strategy that treats cost, velocity, and reliability as one system.
This guide lays out practical cloud strategies for 2025 that help teams spend less and ship faster, without betting the business on a risky rewrite.
What’s different about cloud strategy in 2025?
Cloud strategy used to be mostly about “migrate, modernise, then optimise”. In 2025, teams are dealing with extra pressure and new failure modes:
- Unit economics are scrutinised. Boards want cost per customer, cost per transaction, or cost per API call, not just total spend.
- Kubernetes and platform tooling are mature, but not automatically cheaper. Poor defaults (over-provisioning, noisy telemetry, unmanaged add-ons) still burn money.
- Security and compliance are now schedule drivers. Faster delivery requires safer defaults (policy-as-code, least privilege, audit-ready logs).
- AI workloads change the spend profile. Even if you are not training models, GPUs, vector search, and high-throughput pipelines can create cost spikes.
The best cloud strategies in 2025 start with one principle: every technical decision must map to a measurable business outcome.
Strategy 1: Measure the right costs (not just the bill)
If you only look at the monthly invoice, you’ll optimise in circles. Mature teams track cloud spend as unit costs tied to product value.
Examples:
- Cost per 1,000 requests
- Cost per active customer
- Cost per data pipeline run
- Cost per environment (prod, staging, preview)
To do this, you need two capabilities: reliable allocation and a consistent reporting cadence.
Build cost visibility that engineering can act on
Start with clean allocation, then progressively improve:
- Tagging/label standards (owner, service, environment, cost centre)
- Separate accounts/subscriptions/projects by environment and business domain
- Dashboards that show trends and anomalies, ideally by service and team
A useful mental model is to treat cloud cost management like personal budgeting: you cannot improve what you cannot categorise and review consistently. If you want a simple, practical perspective on building better spending habits, the FIYR personal finance blog is a good read (even for engineers), because it reinforces the core discipline: visibility first, decisions second.
A simple KPI set that balances cost and speed
| KPI | Why it matters | How to measure (practically) |
|---|---|---|
| Cost per service / per team | Creates ownership and eliminates “shared bill” blindness | Tagging + cost allocation reports (weekly) |
| Cost per transaction (or per 1,000 requests) | Links spend to business volume | Combine billing data with request/usage metrics |
| Deployment frequency | Direct signal of delivery flow | CI/CD and Git history |
| Lead time for changes | Shows how fast ideas reach production | PR merge to prod deploy |
| Change failure rate | Speed without stability creates hidden cost | Incident and rollback data |
If you want an industry reference for delivery metrics, the DORA research is a widely used benchmark for measuring software delivery performance.
Strategy 2: Standardise delivery with “golden paths” (platform thinking)
Teams ship faster when they stop reinventing how to build, deploy, secure, and observe services.
In 2025, high-performing engineering organisations increasingly treat the cloud platform as an internal product:
- A small set of approved patterns (for APIs, workers, batch jobs, data pipelines)
- CI/CD templates with built-in quality gates
- Infrastructure as Code (IaC) modules for networks, clusters, databases, identity
- Default observability and security controls
The payoff is compounding: every new service starts closer to production-ready.
What “golden paths” should include
Keep this opinionated and minimal. A strong baseline often includes:
- A reference architecture per workload type (containerised service, serverless, data pipeline)
- Standardised CI/CD pipelines (build, test, scan, deploy)
- GitOps or Git-based promotion for environments
- Policy checks (for example: encryption, private networking, approved base images)
- Monitoring dashboards and alert rules tied to SLOs
This is one of the fastest ways to reduce both cloud waste and delivery friction, because teams spend less time on bespoke plumbing.
Strategy 3: Pick the right compute model for each workload
Many organisations overuse one model (often Kubernetes) for everything. Kubernetes is powerful, but it is not a default cost optimiser.
A better 2025 strategy is to decide compute based on operational overhead, scaling behaviour, and cost predictability.
A pragmatic decision matrix
| Workload | Usually best fit | Why |
|---|---|---|
| Spiky, event-driven tasks | Serverless or event autoscaling | Pay for execution, scale to zero |
| Steady APIs with predictable load | Containers or PaaS | Efficient steady-state cost, controlled rollouts |
| High-performance data processing | Containers on autoscaled compute | Better packing and tuning, spot/preemptible options |
| Legacy apps with constraints | VMs first, then modernise | Reduce risk, stabilise, then iterate |
Two guidance points that reduce regret:
- Prefer managed services when they remove meaningful operational burden (patching, backups, failover), even if the sticker price looks higher.
- Avoid “infrastructure purity”. A mixed approach is common: serverless for glue and event handlers, containers for core services, managed databases for data.
Strategy 4: Make CI/CD a cost optimisation tool (not just a delivery tool)
CI/CD is often framed as “ship faster”. In 2025, it’s also how you spend less.
Here’s how:
- Ephemeral preview environments replace long-running shared staging environments that nobody trusts.
- Automated right-sizing checks prevent oversized requests/limits (a top Kubernetes cost driver).
- Policy-as-code stops expensive mistakes early (public buckets, unrestricted egress, unapproved instance types).
- Progressive delivery (canary/blue-green) reduces incident blast radius and rollback cost.
If your pipelines only run tests and deploy, you are leaving savings on the table.
Strategy 5: Use reliability engineering to cut cloud spend
Reliability is not just “uptime for customers”. It’s also cost control.
Unreliable systems drive:
- Over-provisioning “just in case”
- Expensive incident response and context switching
- Excessive logging and alert spam
- Fear-driven architecture (duplicating systems without clear RTO/RPO targets)
Make SLOs the contract between speed and stability
Define service-level objectives (SLOs) that reflect user experience, then connect them to delivery decisions:
- If error budget is healthy, ship faster.
- If error budget is being burned, slow down and fix systemic issues.
This creates a rational loop where reliability work is not “nice to have”, it is an enabling constraint.
Don’t let observability become your next runaway cost
Telemetry can become a major bill driver, especially with high-cardinality labels and unrestricted log ingestion.
Practical controls that help in 2025:
- Sampling strategies for traces (and adaptive sampling for high-volume endpoints)
- Log retention policies by data class (security, audit, debug)
- Metric cardinality governance (what labels are allowed)
- Budget alerts for observability platforms and ingestion pipelines
Strategy 6: Engineer autoscaling and scheduling to stop paying for idle
“Right-size” is not a one-off task. In modern cloud systems, autoscaling and scheduling are your continuous right-sizing mechanisms.
High-impact tactics:
- Scale based on demand signals (queue depth, request rate, custom metrics), not just CPU
- Turn off non-prod outside working hours where feasible
- Use spot/preemptible capacity for fault-tolerant workloads
- Automate bin packing so you run fewer, better utilised nodes
For Kubernetes teams, that usually means combining:
- Workload autoscaling (HPA/VPA where appropriate)
- Cluster autoscaling (Cluster Autoscaler or Karpenter depending on platform choice)
- Safe disruption controls (Pod Disruption Budgets, multi-AZ spreading)
The key is designing for interruptions and rescheduling from day one, rather than treating it as a cost project later.
A 90-day cloud strategy plan for 2025 (spend less, ship faster)
A strategy without a timeline becomes a slide deck. Here’s a realistic 90-day plan you can adapt.
Days 0 to 30: Baseline and stop the bleeding
Focus on fast clarity and obvious waste:
- Establish cost allocation and ownership by team/service
- Identify and remove idle resources (orphaned volumes, unused load balancers, forgotten environments)
- Set budget alerts for anomalies and sudden spikes
- Baseline delivery metrics (deployment frequency, lead time, failure rate)
This is also the right time to run a light architecture review using a recognised framework like the AWS Well-Architected Framework (especially the Cost Optimisation and Operational Excellence pillars).
Days 31 to 60: Build the “paved road”
Create repeatable delivery and infrastructure patterns:
- Standard CI/CD templates with security scanning and promotion rules
- IaC modules for common infrastructure building blocks
- A minimal golden path for new services
- Default observability dashboards and alerting conventions
The goal is to reduce cognitive load and variation, which improves both speed and cost.
Days 61 to 90: Optimise structurally (not cosmetically)
Now you can tackle the bigger levers:
- Autoscaling based on real demand signals
- Spot/preemptible adoption with resilience guardrails
- Data lifecycle policies (hot, warm, archive) and retention by data class
- SLO-driven on-call and incident reduction work
By the end of 90 days, you should be able to answer two executive questions with evidence:
- “Are we shipping faster?”
- “Is our cost per unit of value going down?”
Common cloud strategy mistakes to avoid in 2025
A few patterns repeatedly derail cost and speed goals:
Optimising cost without fixing delivery flow. If releases are slow, your cloud bill is not the biggest problem. You are paying the hidden tax of low throughput.
Standardising tools instead of outcomes. “Everyone must use Tool X” is not a strategy. “Everyone must be able to deploy safely within 30 minutes” is.
Treating Kubernetes as the destination. Kubernetes is an operating model. Without strong defaults (requests/limits discipline, autoscaling, observability controls, security policies), it often increases spend.
Ignoring egress and data gravity. Data transfer, cross-region traffic, and chatty architectures can quietly dominate costs.
Quick self-check: do you have a 2025-ready cloud strategy?
If you can confidently answer “yes” to most of these, you’re in a strong position:
- We can attribute at least 80% of spend to teams/services/environments.
- We track one unit cost that maps to business value (not just total spend).
- New services start from a golden path (pipeline, IaC, security baseline, observability).
- Deployments are routine and low-risk (not calendar events).
- Autoscaling is based on demand signals, not guesswork.
- We have SLOs for customer-critical services and use error budgets.
If several are “no”, you do not necessarily need a full re-platforming. You likely need a tighter sequence and better defaults.
Frequently Asked Questions
What is the best cloud strategy for 2025? The best cloud strategy for 2025 is outcomes-led: measure unit costs, standardise delivery with golden paths, choose the right compute model per workload, and treat reliability (SLOs, observability, automation) as a cost and speed lever.
How do I reduce cloud costs without slowing down releases? Start with cost visibility and ownership, then use platform standardisation (IaC modules, CI/CD templates, policy-as-code) so teams spend less time on bespoke work. Finally, apply structural optimisations like autoscaling, scheduling non-prod, and spot/preemptible capacity with the right resilience controls.
Is Kubernetes always cheaper in 2025? No. Kubernetes can be cost-effective at scale, but only with disciplined resource requests/limits, autoscaling, node utilisation, and telemetry governance. Without these, it often increases both spend and operational load.
What should I measure to prove cloud ROI? Track a mix of cost and delivery KPIs: cost per transaction (or per customer), cost per service/team, deployment frequency, lead time for changes, change failure rate, and reliability metrics tied to SLOs.
How quickly can we see results from a cloud strategy reset? Many teams see meaningful improvements in 30 to 90 days, especially from better cost allocation, removing idle resources, standardising CI/CD and IaC, and implementing safer autoscaling patterns.
Turn cloud strategy into measurable outcomes with Tasrie IT Services
If your 2025 priority is to spend less and ship faster, the fastest path is usually a focused engagement that establishes cost visibility, delivery standards, and production-ready automation (without boiling the ocean).
Tasrie IT Services supports engineering teams with senior, outcome-driven consulting across DevOps, Kubernetes, cloud infrastructure, security, automation, and observability. If you want to discuss your current bottlenecks and what a pragmatic 90-day plan could look like, visit Tasrie IT Services and get in touch.