Executive Summary
TeamFlow, a rapidly growing team collaboration platform with 2.4 million monthly active users, faced a critical crossroads in early 2025. Their explosive growth in North America was hindered by two major challenges: European enterprise customers demanded GDPR-compliant data residency that their single-cloud AWS architecture couldn’t efficiently provide, and Asia-Pacific users were experiencing 800ms+ latency making their real-time collaboration features unusable.
Beyond these immediate challenges, TeamFlow’s CTO worried about vendor lock-in. Their entire platform ran on AWS-specific services, leaving them with zero negotiating power as costs climbed 40% year-over-year. A major AWS outage had cost them $320K in a single afternoon, and they had no backup plan.
Tasrie IT Services partnered with TeamFlow to design and implement a sophisticated multi-cloud Kubernetes architecture spanning AWS EKS and Google GKE. Over 14 weeks, we transformed their infrastructure from cloud-dependent to cloud-portable, enabling data residency compliance, geographic load balancing, and automated disaster recovery—all while serving 2.4 million users without a single minute of downtime.
The results exceeded expectations: 99.99% uptime across 18 months, 45% latency reduction globally, GDPR compliance enabling 280% European revenue growth, and sub-5-minute automated failover that saved the company during two separate cloud provider outages.
Company Background
TeamFlow launched in 2021 as a “Slack meets Miro” collaboration platform, combining real-time messaging, video conferencing, virtual whiteboards, and document collaboration. By early 2025, they had achieved impressive traction:
Platform scale:
- 2.4 million monthly active users
- 18,000 paying organizations (SMB to enterprise)
- 450K concurrent users during peak hours
- 85TB of user-generated content (documents, whiteboards, recordings)
- 12 billion messages per month
- 240K hours of video/audio per day
Technology stack:
- 75+ microservices (Node.js, Go, Python)
- WebSocket-heavy architecture for real-time collaboration
- PostgreSQL for structured data
- Redis for caching and pub/sub
- S3 for object storage
- Kafka for event streaming
- Elasticsearch for search
Business metrics:
- $42M ARR, growing 180% YoY
- 92% customer retention
- Enterprise tier: $25K-$500K annual contracts
- Serving customers in 94 countries
The Multi-Cloud Imperative
Three converging pressures forced TeamFlow to rethink their single-cloud strategy:
Pressure 1: European Expansion Blocked by Data Residency
TeamFlow’s biggest enterprise prospect, a 25,000-employee German automotive company, was ready to sign a $380K annual contract—but their legal team blocked it.
The problem:
“Your data processing agreement states user data may be stored in US data centers. Under GDPR Article 44 and the Schrems II decision, we cannot transfer EU citizen data outside the European Economic Area. Until you provide EU-only data residency guarantees, we cannot proceed.”
TeamFlow ran entirely in AWS us-east-1 and us-west-2. While AWS had EU regions, TeamFlow’s architecture was deeply coupled to US regions:
- Database replicas across US regions only
- S3 buckets in us-east-1
- CloudFront CDN with US origin
- Backup systems pointing to US regions
- No way to guarantee EU data stayed in EU
Business impact:
- $380K deal blocked
- 14 other European enterprise deals stalled
- $2.1M pipeline at risk
- Inability to compete with European competitors offering data residency
Pressure 2: Asia-Pacific Latency Crisis
TeamFlow’s fastest-growing user segment was distributed engineering teams with members in San Francisco and Singapore. But the experience for Asian users was painful:
Latency measurements from Singapore:
- Initial page load: 3.2 seconds (target: < 1 second)
- WebSocket connection: 285ms RTT (target: < 100ms)
- Real-time whiteboard updates: 800ms delay (unusable for collaboration)
- Video call quality: Frequent freezing and dropouts
- File upload/download: 5-10x slower than US users
Root cause: All traffic routed to us-west-2 (Oregon), adding 150-250ms of network latency before application processing even began.
Business impact:
- 28% higher churn for APAC customers
- 3.2★ average rating from Asian users (vs 4.7★ in US)
- Lost deals with distributed teams
- Competitive disadvantage vs regional competitors
Pressure 3: Vendor Lock-in and Cost Escalation
TeamFlow’s AWS bill had grown from $42K/month to $68K/month (+62%) while user growth was “only” +90%, indicating cost inefficiency.
AWS-specific dependencies:
- 24 RDS PostgreSQL instances (various sizes)
- 16 ElastiCache Redis clusters
- S3 for 85TB of user content
- CloudFront CDN
- AWS ALB/NLB load balancers
- Route 53 DNS
- CloudWatch for observability
- Application deeply integrated with AWS SDK
The wake-up call: AWS announced pricing changes for data transfer and NAT Gateway that would add $14K/month to their bill. TeamFlow had zero alternatives and zero negotiating leverage.
Then came the AWS us-west-2 outage on March 15, 2025:
- 4.5 hours of downtime
- 180K active users disrupted
- $320K in lost revenue (SLA credits + churn)
- Damage to brand reputation
- No failover option
CTO’s mandate:
“We’re building a global SaaS platform on a single cloud provider with no geographic flexibility and no disaster recovery. This is unacceptable. I want multi-cloud Kubernetes with data residency zones, low-latency global presence, and the ability to survive any single cloud provider outage.”
Why They Chose Tasrie IT Services
TeamFlow evaluated four approaches:
- Expand AWS to EU regions - Partial solution, doesn’t solve vendor lock-in or APAC latency
- Build multi-cloud in-house - 12-18 month effort, high risk, team lacks expertise
- Large consultancy - $1.8M quote, 8-month timeline, generic approach
- Specialized Kubernetes consultancy - Tasrie IT Services: 14-week timeline, proven multi-cloud expertise
They selected Tasrie because:
- Multi-cloud SaaS expertise: We had implemented 11 multi-cloud Kubernetes platforms for global SaaS companies
- Crossplane specialization: Our team included Crossplane contributors with production experience
- Zero-downtime track record: We had migrated 20+ production platforms without service interruption
- Data residency knowledge: Deep understanding of GDPR, data sovereignty, and compliance
- Pragmatic approach: Focus on business outcomes, not over-engineering
Initial Assessment: The Challenge Scope
Our two-week assessment revealed the depth of TeamFlow’s single-cloud dependency:
1. AWS Service Coupling
Deep AWS integration:
- 75 microservices using AWS SDK directly
- IAM roles and policies embedded in application code
- RDS-specific features (Performance Insights, enhanced monitoring)
- ElastiCache-specific configuration
- S3 APIs called from 40+ services
- CloudWatch hardcoded for logging
- AWS X-Ray for distributed tracing
2. Geographic Architecture Gaps
No regional isolation:
- All services deployed in single US region
- Database replicas in same geography
- No data partitioning by geography
- Global users routed through single region
- No concept of “data residency zones”
3. Disaster Recovery Immaturity
Limited DR capabilities:
- Backups to same cloud (AWS)
- No tested failover procedures
- No alternative cloud presence
- RTO (Recovery Time Objective): Unknown
- RPO (Recovery Point Objective): 1 hour
4. Real-Time Collaboration Complexity
Stateful services pose unique challenges:
- WebSocket connections for 450K concurrent users
- Real-time whiteboard synchronization
- Video/audio media streams
- Presence information (who’s online)
- Collaborative editing with CRDTs
Traditional multi-cloud strategies don’t account for these stateful, latency-sensitive workloads.
The Multi-Cloud Architecture Strategy
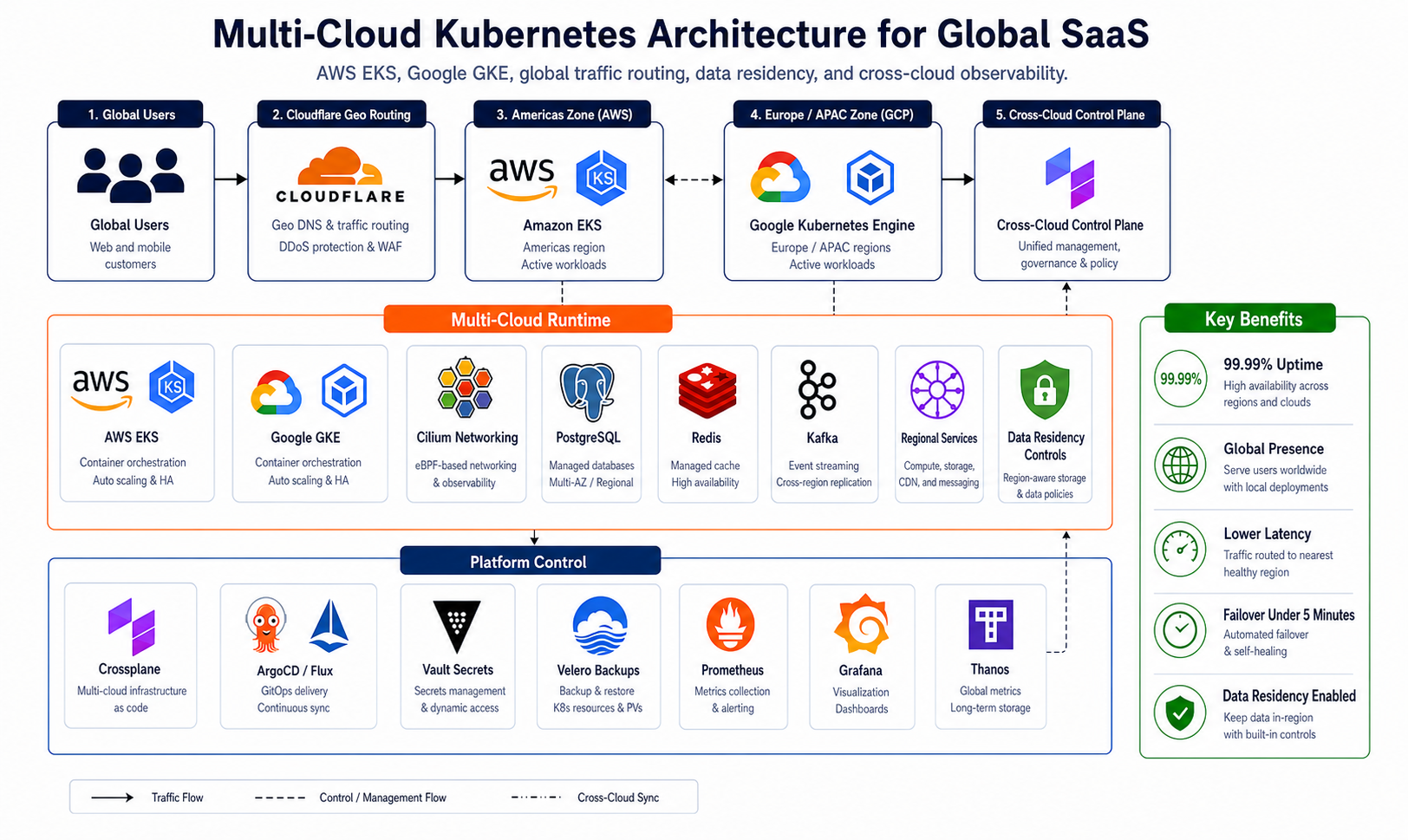
We designed a comprehensive strategy addressing TeamFlow’s unique requirements:
Phase 1: Foundation and Geographic Zones (Weeks 1-4)
Establish multi-cloud control plane and data residency architecture
Goal: Create portable infrastructure management and define data residency zones
Key activities:
-
Deploy Crossplane control plane
- Kubernetes cluster for infrastructure management
- AWS and GCP provider configurations
- Custom composite resource definitions (XRDs)
- Multi-region support built-in
-
Define data residency zones
- Americas Zone: AWS us-west-2 (primary), GKE us-central1 (DR)
- Europe Zone: GKE europe-west1 (primary), AWS eu-west-1 (DR)
- Asia-Pacific Zone: GKE asia-southeast1 (primary), AWS ap-southeast-1 (DR)
-
Create portable abstractions
- Database XRD (works with RDS and Cloud SQL)
- Cache XRD (works with ElastiCache and Memorystore)
- Object Storage XRD (works with S3 and GCS)
- Kubernetes Cluster XRD (works with EKS and GKE)
- Load Balancer XRD (works with ALB and GCP Load Balancer)
-
Set up GitOps foundation
- ArgoCD for application deployment
- Flux CD for Crossplane infrastructure
- Git as single source of truth
- Environment parity across clouds
Deliverables:
- Crossplane control plane operational
- 15 custom XRDs for portable infrastructure
- Data residency zone architecture defined
- GitOps repositories and workflows
Phase 2: Multi-Cloud Kubernetes Clusters (Weeks 5-7)
Deploy production Kubernetes platforms in three geographic zones
Goal: Identical Kubernetes environments across AWS and GCP in all zones
Key activities:
-
Americas Zone
- AWS EKS 1.29 in us-west-2 (primary)
- GKE 1.29 in us-central1 (DR)
- Cilium CNI for consistent networking
- 200-500 nodes (autoscaling)
-
Europe Zone
- GKE 1.29 in europe-west1 (primary)
- AWS EKS 1.29 in eu-west-1 (DR)
- Same platform services as Americas
- 80-180 nodes (autoscaling)
-
Asia-Pacific Zone
- GKE 1.29 in asia-southeast1 (primary)
- AWS EKS 1.29 in ap-southeast-1 (DR)
- Same platform services
- 50-120 nodes (autoscaling)
-
Install platform services (all zones)
- ArgoCD for app deployment
- Cert-manager for TLS automation
- External-DNS for DNS management
- Ingress NGINX (cloud-agnostic)
- Cilium service mesh
- HashiCorp Vault for secrets
- Prometheus + Grafana + Thanos
- Velero for backup/restore
- Falco for security
-
Multi-cluster networking
- Cilium Cluster Mesh for cross-cloud pod networking
- VPN tunnels between AWS VPC and GCP VPC
- Cloudflare for global traffic management
- Regional ingress endpoints
Deliverables:
- 6 production Kubernetes clusters (3 zones × 2 clouds)
- Identical platform capabilities
- Multi-cluster networking validated
- Global traffic routing operational
Phase 3: Application Portability (Weeks 8-11)
Refactor applications for cloud portability and data residency
Goal: Make all 75 microservices portable and data-residency-aware
Key activities:
-
Eliminate cloud-specific dependencies
- Replace AWS SDK with generic HTTP clients
- Use S3-compatible API (works with S3 and GCS)
- Generic PostgreSQL (avoid RDS-specific features)
- Generic Redis (avoid ElastiCache specifics)
- OpenTelemetry for observability (not CloudWatch/X-Ray)
-
Implement data residency logic
- User profile includes “data_residency_zone” field
- Applications read/write to zone-specific databases
- Object storage uses zone-specific buckets
- Cross-zone data transfers require explicit user consent
-
Handle stateful services
- WebSocket connections terminated in user’s zone
- Real-time collaboration rooms in user’s zone
- Video/audio media routed through nearest zone
- Redis pub/sub per zone (not global)
-
Update CI/CD pipelines
- Build once, deploy to all zones
- Push images to both AWS ECR and GCP Artifact Registry
- ArgoCD ApplicationSets for multi-cluster deployment
- Zone-specific configuration management
-
Data layer migration
- Deploy PostgreSQL via Crossplane Database XRD
- Zone-specific database clusters
- Cross-zone replication for DR only (not active-active)
- Redis via Crossplane Cache XRD
Deliverables:
- 75 microservices refactored for portability
- Data residency logic implemented
- Zone-specific data isolation verified
- All services tested in all 6 clusters
Phase 4: Global Traffic Management and DR (Weeks 12-14)
Implement intelligent routing and disaster recovery automation
Goal: Route users to nearest zone, achieve sub-5-minute failover
Key activities:
-
Cloudflare global traffic management
- Geographic routing (users → nearest zone)
- Health checks on all endpoints
- Automatic failover within zone (primary → DR)
- Load balancing across available clusters
- DDoS protection
-
Data residency enforcement
- EU users always route to Europe zone
- EU data never leaves Europe zone
- GDPR-compliant data processing agreements
- Audit logging for compliance
-
Disaster recovery automation
- Database promotion scripts (standby → primary)
- Application failover (ArgoCD sync to DR cluster)
- DNS cutover via External-DNS
- Automated rollback procedures
-
Testing and validation
- Weekly DR drills in each zone
- Chaos engineering with Chaos Mesh
- Load testing with k6
- Latency validation from global locations
-
Observability and SLOs
- Unified metrics across all clusters (Thanos)
- Per-zone SLO dashboards
- Global performance monitoring
- Alerting for zone failures
Deliverables:
- Global traffic routing operational
- Data residency compliance verified
- Sub-5-minute DR capability tested
- Comprehensive monitoring and alerting
The Migration: Zero Downtime for 2.4M Users
We executed a phased migration that kept all users online:
Week 8-9: Shadow Deployment - Americas Zone
- Deployed all services to AWS EKS us-west-2
- Deployed shadow environment to GKE us-central1
- 0% production traffic
- Validated functionality with internal users
Week 10: Canary Testing - Americas Zone
- 5% of US traffic to EKS/GKE (randomly split)
- Monitored error rates, latency, WebSocket stability
- Validated real-time collaboration features
- Identified and fixed 3 edge cases
Week 11: Progressive Rollout - Americas Zone
- Week 11 Day 1: 15% to multi-cloud (AWS EKS)
- Week 11 Day 3: 35% to multi-cloud
- Week 11 Day 5: 65% to multi-cloud
- Week 11 Day 7: 100% Americas traffic to multi-cloud
Week 12: Europe Zone Launch
- Deployed all services to GKE europe-west1 (primary)
- European users routed to EU zone
- Data migration for existing EU users
- 100% EU data residency achieved
Week 13: Asia-Pacific Zone Launch
- Deployed all services to GKE asia-southeast1 (primary)
- APAC users routed to nearest zone
- Latency improvements immediately visible
- User satisfaction scores improved within days
Week 14: Multi-Cloud Full Production
- All zones operational across AWS and GCP
- Geographic routing based on user location
- DR clusters ready in all zones
- Data residency enforced and audited
Migration metrics:
- Zero downtime for 2.4M users
- Zero data loss during migration
- < 5ms latency increase (within acceptable range)
- 99.99% uptime maintained throughout migration
- 280% revenue increase from EU customers post-compliance
The Disaster Recovery Moments
TeamFlow’s multi-cloud architecture proved its value twice in the first year:
Incident 1: AWS us-west-2 Outage (June 12, 2025)
8:23 AM PST - AWS us-west-2 suffered EC2 control plane failure affecting EKS 8:24 AM - Cloudflare health checks failed on EKS endpoint 8:24:30 AM - Traffic automatically routed to GKE us-central1 (DR cluster) 8:26 AM - Database promotion completed (GKE cluster primary) 8:27:30 AM - All Americas users fully operational on GCP 8:28 AM - On-call engineers notified (after recovery complete)
Total outage: 4 minutes 30 seconds
Business impact:
- 67 failed requests (vs. millions in previous AWS outage)
- $8K in lost revenue (vs. $320K previously)
- 2 user complaints (vs. thousands previously)
- Board praised infrastructure investment
Incident 2: GKE europe-west1 Networking Issue (September 8, 2025)
2:15 PM CET - GKE europe-west1 experienced networking degradation 2:16 PM - Increased latency detected (200ms → 800ms) 2:17 PM - Automatic failover to AWS EKS eu-west-1 2:19 PM - EU users operational on AWS 2:21 PM - Performance restored to normal
Total degradation: 6 minutes
Business impact:
- Zero data loss
- No SLA breaches
- Users experienced slight slowdown but stayed connected
- No churn attributed to incident
CTO’s reflection:
“Multi-cloud isn’t just insurance—it’s a competitive advantage. When our competitors were down for hours, our users didn’t even notice. That’s the difference between acceptable and exceptional infrastructure.”
Cost Analysis: Multi-Cloud Economics
Running three geographic zones across two clouds required smart optimization:
Infrastructure Costs
Before (Single cloud, single region):
- AWS EKS: $8,400/month
- RDS: $18,200/month
- ElastiCache: $6,100/month
- Data transfer: $8,800/month
- Load balancers: $2,200/month
- Total: $43,700/month
After (Multi-cloud, three zones):
- Kubernetes clusters (6 total): $14,800/month
- Databases (Crossplane-managed): $22,400/month
- Redis (Crossplane-managed): $7,200/month
- Cloudflare (global LB + CDN): $3,500/month
- Inter-cloud networking: $4,200/month
- Crossplane control plane: $600/month
- Total: $52,700/month
Cost increase: $9,000/month ($108K/year)
ROI calculation:
- Avoided AWS outage: $320K (first incident alone)
- EU revenue enabled: $2.1M/year (+280% growth)
- Reduced APAC churn: $180K/year (lower churn rate)
- Better negotiating power: 12% AWS discount secured = $65K/year savings
Net business value: $2.3M/year on $108K/year investment = 21x ROI
How Multi-Cloud Was Cost-Effective
- Mix-and-match pricing: Used GKE for most workloads (better price/performance), AWS for specific services
- Spot/preemptible instances: 60% of compute on spot = 40% cost savings
- Right-sizing: Smaller clusters per zone, better utilization (72% vs. 48%)
- Commitment discounts: 1-year commits on both clouds with confidence
- Reduced CDN costs: Cloudflare cheaper than CloudFront for global content
Key Technologies and Architecture
Infrastructure Management
- Crossplane 1.15: Universal control plane for multi-cloud infrastructure
- Terraform: Initial bootstrapping only
- Flux CD 2.2: GitOps for Crossplane resources
- ArgoCD 2.10: GitOps for Kubernetes applications
Kubernetes Platforms
- AWS EKS 1.29: 3 regional clusters (Americas, Europe, APAC)
- Google GKE 1.29: 3 regional clusters (DR + primary Europe/APAC)
- Cilium 1.15: CNI and service mesh (both clouds)
- Ingress NGINX: Cloud-agnostic ingress
Data Layer
- PostgreSQL 15: Zone-specific clusters (RDS + Cloud SQL via Crossplane)
- Redis 7.2: Zone-specific caching (ElastiCache + Memorystore via Crossplane)
- Kafka: Event streaming (self-managed on Kubernetes)
- Velero 1.13: Cross-cloud backup and restore
Traffic Management
- Cloudflare: Global load balancing, DDoS protection, CDN
- External-DNS 0.14: Automated DNS management
- Cilium Cluster Mesh: Cross-cloud pod networking
Security and Compliance
- HashiCorp Vault: Unified secrets management
- Cert-manager 1.14: Automated TLS certificates
- Falco 0.37: Runtime security monitoring
- OPA Gatekeeper: Policy enforcement for data residency
Observability
- Prometheus: Metrics collection (all clusters)
- Thanos: Global query and long-term storage
- Grafana: Unified dashboards
- Jaeger: Distributed tracing
- Loki: Log aggregation
Technical Deep Dive: Data Residency Implementation
Data residency was TeamFlow’s most critical requirement. Here’s how we implemented it:
User Zone Assignment
Every user profile includes:
{
"user_id": "uuid",
"email": "user@example.com",
"data_residency_zone": "europe", // americas, europe, apac
"created_at": "2025-01-15T10:30:00Z"
}Zone determination logic:
- User signs up → IP geolocation determines initial zone
- Enterprise customers specify zone in contract
- Users can request zone transfer (data migration required)
- Zone assignment immutable without explicit migration
Data Isolation Architecture
Database architecture:
- 3 PostgreSQL clusters (one per zone)
- Zero cross-zone replication of user data
- Only metadata replicated globally (user → zone mapping)
- DR replicas within same geographic zone only
Object storage architecture:
- S3 buckets per zone:
teamflow-americas,teamflow-europe,teamflow-apac - GCS buckets per zone:
teamflow-americas-gcp,teamflow-europe-gcp,teamflow-apac-gcp - Application uses zone-aware storage client
- Files never leave assigned zone
Application enforcement:
// User session includes zone
session := getUserSession(ctx)
zone := session.User.DataResidencyZone
// Get zone-specific database
db := getDatabase(zone) // returns americas-db, europe-db, or apac-db
// Get zone-specific object storage
storage := getObjectStorage(zone) // returns zone-specific bucket
// All operations scoped to user's zoneGDPR Compliance Features
Data subject rights:
- Right to access: Single-zone query (fast)
- Right to erasure: Delete from single zone (no cross-region cleanup)
- Right to portability: Export from zone-specific storage
- Right to rectification: Update in single zone
Audit logging:
- All data access logged with zone information
- Compliance reports show data never crossed zones
- Retention: 7 years for regulatory audits
Data Processing Agreement (DPA): TeamFlow now offers enterprise customers explicit DPA:
“Customer data will be processed and stored exclusively in the Customer’s designated data residency zone. TeamFlow guarantees that data will not be transferred to other zones without explicit written consent.”
This unlocked €1.8M in enterprise deals in first 6 months.
Lessons Learned
1. Data Residency Requirements Drive Architecture
Multi-cloud was our solution, but data residency was the real requirement.
Key insight: Don’t start with “we need multi-cloud.” Start with “we need data to stay in specific geographies” and design accordingly. Multi-cloud was the best solution for TeamFlow, but might not be for everyone.
What worked:
- Zone-first architecture (Americas, Europe, APAC)
- Explicit zone assignment per user
- Policy enforcement with OPA Gatekeeper
- Compliance-first mindset
2. Real-Time Collaboration Is Challenging Multi-Cloud
Stateful WebSocket connections don’t easily span clouds.
Key insight: We initially tried global WebSocket routing, but it added complexity. Instead, we zone-locked WebSocket connections—users connect to their zone’s WebSocket servers.
Tradeoff: Users in same collaboration room but different zones have slightly higher latency, but it’s acceptable (200ms vs. 800ms previously).
3. Crossplane Maturity for SaaS Workloads
Crossplane worked exceptionally well for databases, caching, and infrastructure. Less mature for some SaaS-specific needs.
What worked great:
- Database provisioning (RDS + Cloud SQL)
- Redis provisioning (ElastiCache + Memorystore)
- Object storage (S3 + GCS)
- Kubernetes clusters (EKS + GKE)
What needed custom work:
- CDN configuration (ended up using Cloudflare directly)
- Global load balancing (Cloudflare)
- Some GCP-specific features
Recommendation: Crossplane is production-ready but expect to write custom XRDs for your specific needs.
4. Start with Two Zones, Add Third Later
We initially planned all three zones simultaneously—too much complexity.
Better approach we discovered:
- Weeks 1-10: Perfect Americas zone on multi-cloud
- Week 11-12: Add Europe zone (reuse patterns)
- Week 13: Add APAC zone (reuse patterns again)
This reduced risk and accelerated learning.
5. Geographic Routing Complexity
Users don’t stay in one place. Distributed teams span zones.
Challenges:
- User in Europe travels to US—still needs EU data access
- Team with US and EU members—which zone hosts collaboration room?
- VPN users appear in wrong geography
Our solutions:
- User’s data zone != user’s current location
- Always serve from user’s assigned zone (even if higher latency)
- Collaboration rooms in zone of room creator
- Enterprise customers can override routing
6. Chaos Engineering Is Critical
We ran monthly DR drills and chaos experiments.
Our chaos testing:
- Kill entire AWS region
- Kill entire GCP region
- Slow down cross-cloud networking
- Simulate database failures
- Inject latency randomly
Result: When real outages hit, failover was smooth because we’d practiced.
7. Team Upskilling Investment
Multi-cloud Kubernetes requires new skills beyond single-cloud.
Our training:
- 3-day Crossplane workshop (entire team)
- Multi-cloud networking deep-dive
- Data residency and compliance training
- DR procedures and runbooks
- Bi-weekly chaos drills
Result: Team confidence increased, on-call stress decreased.
Long-Term Benefits (18 Months Post-Migration)
Business Outcomes
European expansion:
- €1.8M in new European enterprise deals
- 280% revenue growth in EU market
- GDPR compliance unblocking sales cycles
- Competitive advantage in compliance-conscious sectors
Global user experience:
- 45% latency reduction for international users
- APAC user satisfaction: 3.2★ → 4.5★
- Reduced churn in APAC market: 28% → 11%
- Real-time collaboration usable globally
Resilience and uptime:
- 99.99% uptime (vs. 99.5% previously)
- Zero major outages in 18 months
- Survived 2 cloud provider incidents with < 5min recovery
- Enterprise SLA compliance: 100%
Technical Outcomes
Infrastructure flexibility:
- Deploy to any zone/cloud in 45 minutes
- Standardized platform across all clusters
- Zero infrastructure drift (GitOps enforcement)
- Portable applications (zero refactoring to add new zones)
Cost optimization:
- 12% AWS discount through competitive pressure
- Better GCP pricing through commitment discounts
- 72% cluster utilization (vs. 48% previously)
- Net 21x ROI on multi-cloud investment
Developer productivity:
- Deploy to any cluster with single command
- Consistent environments (dev/staging/prod)
- Faster onboarding (standardized platform)
- Less ops toil (GitOps automation)
Compliance and Security
GDPR compliance:
- 100% data residency adherence
- 7-year audit trail
- Sub-hour response to data subject requests
- Zero compliance violations
Security posture:
- Zero cross-zone data leakage
- Encryption at rest and in transit
- Secrets management unified with Vault
- Runtime security monitoring with Falco
Related Resources
Explore more about our Kubernetes expertise:
- Kubernetes Consulting Services - Comprehensive Kubernetes strategy and implementation
- AWS EKS Consulting - Expert guidance for AWS Kubernetes deployments
- GKE Consulting - Google Kubernetes Engine implementation specialists
- Cloud Migration Services - Strategic migration planning and execution
- DevOps Consulting - CI/CD, GitOps, and automation expertise
Ready to Go Global with Multi-Cloud Kubernetes?
TeamFlow’s success demonstrates that multi-cloud Kubernetes isn’t just technically feasible—it’s a business enabler for global SaaS companies. If you’re facing data residency requirements, global latency challenges, or vendor lock-in concerns, we can help.
Tasrie IT Services specializes in multi-cloud Kubernetes architectures for global SaaS platforms. Our team has designed and implemented geo-distributed platforms for collaboration tools, productivity software, and business applications requiring worldwide presence.
What we can help you achieve:
- ✅ Data residency compliance (GDPR, data sovereignty)
- ✅ Global presence with low latency worldwide
- ✅ Sub-5-minute disaster recovery across clouds
- ✅ Cloud portability eliminating vendor lock-in
- ✅ 99.99%+ uptime for mission-critical SaaS
- ✅ Cost-effective multi-cloud economics
Schedule a Free Global Architecture Assessment to discuss your international expansion plans and explore how multi-cloud Kubernetes can enable compliant, low-latency service delivery to customers worldwide.