If you are running Kubernetes in production, “working deployments” are not the same as repeatable, auditable, low-risk delivery. The difference usually comes down to whether your platform treats Git as the single source of truth (GitOps), whether you have a consistent packaging strategy (Helm), and whether you have a reliable, pull-based deployment controller (Argo CD).
This playbook is a practical blueprint for building that stack without turning it into a science project.
The operating model: what “GitOps” actually changes
GitOps is not “CI/CD with Git”. It is an operating model where:
- Desired state is declared (Kubernetes manifests, Helm chart values, policies) and stored in Git.
- A controller reconciles the live cluster to match that desired state (pull-based, not push-based).
- Every change is reviewable and attributable (PRs, approvals, commit history), making audits and incident analysis significantly easier.
In practice, GitOps shifts deployment responsibility from “a pipeline running kubectl” to “a continuously running reconciler” that can detect drift, self-heal, and enforce consistency.
A helpful way to explain GitOps in a DevOps context is to separate responsibilities:
| Concern | CI (build-time) | CD via GitOps (runtime) |
|---|---|---|
| Typical owner | Product teams | Platform/SRE with guardrails |
| Trigger | Commit, PR merge, tag | Git change observed by controller |
| Output | Immutable artefacts (images, charts) | Reconciled cluster state |
| Safety focus | Tests, scanning, provenance | Policy, progressive delivery, drift control |
For reference, the original GitOps framing came from the Kubernetes community; Flux popularised the term and the model has since been adopted broadly across CNCF tooling.
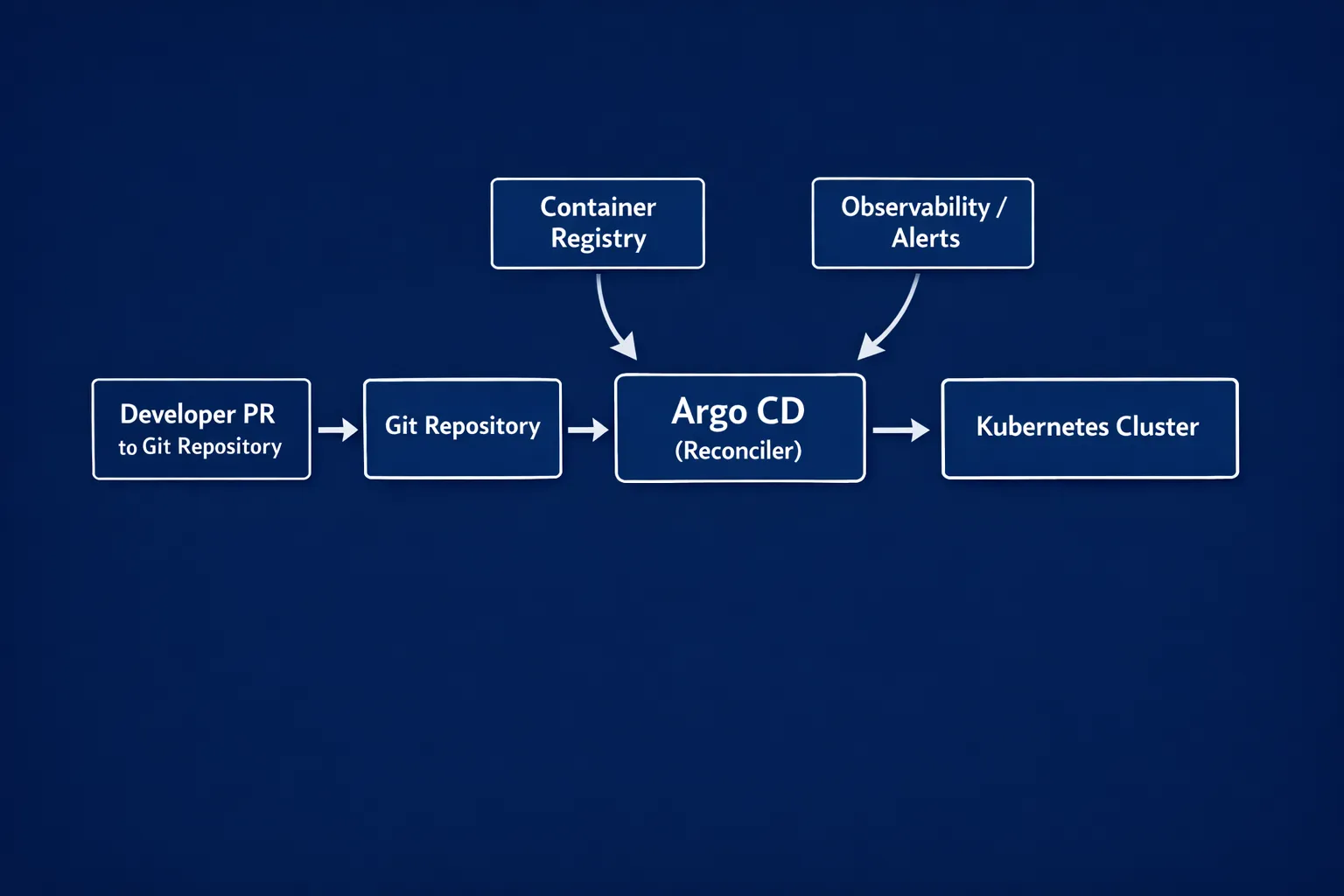
The minimum viable GitOps architecture (what to standardise first)
Before Helm templates or Argo CD Applications, align on a few non-negotiables.
1) One repo or two repos?
Most teams converge on one of these patterns:
- Mono-repo for app + config: simpler for small teams, faster change loops.
- Split repos: one repo for application code, one for environment config (often called “gitops repo”). Better separation of duties and access control.
If you have compliance constraints (regulated workloads, SOC 2), split repos typically scale better because config approvals and secrets controls can be tightened without slowing down feature development.
2) Promotion model: how does change move to production?
A GitOps controller will happily deploy whatever you commit, so you need an explicit promotion mechanism:
- Branch-per-environment (dev, staging, prod) is simple but can become messy with many services.
- Folder-per-environment (recommended for many teams) keeps promotion as a PR that changes a version field or values file.
- Tag-based promotion works well when combined with release automation.
The key is that production promotion should be a small, reviewable diff, ideally “bump image tag” or “bump chart version”.
3) Decide what “drift” means and how to handle it
Drift is not always bad. For example, autoscalers and controllers will legitimately change replica counts.
Set expectations up front:
- Argo CD should enforce configuration drift (manifests, configmaps, RBAC).
- Autoscaling and runtime controllers should be allowed to adjust operational fields.
Argo CD supports ignore differences rules for specific fields, which is essential for avoiding noisy drift alerts.
Helm in a GitOps world: packaging without YAML sprawl
Helm is the packaging layer that helps you manage multi-environment Kubernetes configuration without duplicating manifests.
Use Helm for these jobs
Helm excels when you need:
- Reusable charts shared across teams (platform “golden paths”).
- Controlled parameterisation via
values.yaml(per environment, per region). - Dependency management (databases, ingress controllers, observability agents).
Avoid Helm for these jobs
Helm becomes painful when you use templates to encode business logic or conditional spaghetti. If your chart reads like a programming language, you are likely using Helm to compensate for missing platform standards.
A good rule: templates should define structure, values should define behaviour.
Recommended Helm structure for multi-environment deployments
A pragmatic layout that stays readable as you scale:
- Chart contains the Kubernetes objects and sane defaults.
- Each environment has a small values file (or a few values files) that overrides only what must differ.
Example environment overrides you can justify:
- Resource requests/limits
- Replica baseline (if not purely autoscaled)
- External endpoints (hostnames)
- Feature flags that must differ per environment
What you should avoid varying per environment:
- Entirely different Kubernetes object shapes
- Random extra manifests only in prod
That last point is a common root cause of “it worked in staging” incidents.
Argo CD: the delivery controller that makes GitOps real
Argo CD continuously reconciles Kubernetes resources from Git. Conceptually, it provides:
- Application objects that map a Git path (or Helm chart) to a cluster/namespace.
- Sync policies (auto-sync, prune, self-heal) and safe deployment controls.
- RBAC and projects for multi-team separation.
- Drift detection and visibility into what changed and why.
The best starting point is the official docs for Argo CD and its model of desired state reconciliation.
Core Argo CD building blocks (and what they are for)
| Argo CD concept | What it controls | Why it matters |
|---|---|---|
| Application | A deployable unit | Gives you a clear boundary for sync, health, and ownership |
| Project | A policy boundary | Restricts destinations, source repos, and allowed kinds |
| Sync policy | How changes apply | Enables auto-sync, pruning, self-heal, retries |
| Health checks | What “healthy” means | Prevents false success when Pods are running but app is broken |
The “App of Apps” pattern (platform scale without chaos)
Most organisations end up needing a way to bootstrap and manage many applications consistently.
With “App of Apps”, you create a root Argo CD Application that points to a folder of child Application manifests. This gives you:
- A single place to view platform rollout state
- A consistent structure for adding new services
- Easier environment bootstrapping (new cluster, new region)
If you do this, keep the root app very boring. It should be a thin orchestrator, not a mega-chart.
Putting it together: a practical repository blueprint
A common, scalable split looks like this:
- Application repo: code, Dockerfile, Helm chart (or chart reference), CI pipelines
- GitOps repo: environment definitions, Argo CD Applications, values overrides
One approach that works well for mid-market and enterprise teams:
/apps/<service>/basefor shared config/apps/<service>/envs/dev|staging|prodfor environment-specific values/clusters/<cluster-name>/appsto define what runs where
This structure makes it obvious which change is a service-level change versus a cluster-level rollout decision.
CI/CD boundary: what goes in CI, what goes in GitOps CD?
A reliable split is:
CI responsibilities
- Build and tag container images (prefer immutable tags)
- Run unit/integration tests
- Run security scans (SAST, dependency, container image)
- Publish artefacts (image to registry, chart to registry)
GitOps CD responsibilities
- Deploy the exact artefacts that passed CI
- Enforce environment policies (namespace boundaries, allowed kinds)
- Reconcile drift, handle rollbacks, and provide deployment visibility
This separation is one of the fastest ways to reduce “pipeline fragility” because a broken CI runner no longer blocks reconciliation of already-approved state.
Secrets: the part teams get wrong first
GitOps increases transparency, so secrets handling must be intentional.
In Kubernetes GitOps, you typically choose one of these approaches:
- External Secrets Operator (sync from AWS Secrets Manager, Azure Key Vault, HashiCorp Vault)
- Sealed Secrets (encrypted secrets committed to Git)
- SOPS (encrypt YAML/JSON with KMS/PGP and decrypt at deploy time)
The best choice depends on your cloud and compliance model, but the principle stays the same: Git should store either references to secrets, or encrypted secrets, never plaintext.
Progressive delivery: safer rollouts without slowing teams down
Argo CD is a continuous delivery controller, but progressive delivery (canary, blue-green) usually needs an additional strategy.
Common patterns include:
- Using Argo Rollouts for canary and blue-green
- Using service mesh capabilities (Istio, Linkerd) or ingress traffic splitting where appropriate
Whatever you choose, define a “minimum safe deployment standard” for production:
- A readiness probe and liveness probe that reflect real app health
- A rollback plan (automated or well-rehearsed)
- Observability that lets you validate the release (metrics, logs, traces)
This is especially important for customer-facing platforms where peak traffic windows create real business risk, for example an event equipment rental provider that must keep booking and quoting workflows online during busy weekends.
Policy and guardrails: GitOps scales only with constraints
As soon as more than one team deploys to Kubernetes, you need guardrails that are enforced automatically.
Practical guardrails that pay off early:
- Namespace-level quotas and limit ranges
- Pod Security Standards (baseline or restricted where feasible)
- Network policies for workload isolation
- Admission control with policy-as-code (OPA Gatekeeper or Kyverno)
In Argo CD, use Projects to restrict:
- Which repos a team can deploy from
- Which namespaces/clusters they can target
- Which Kubernetes kinds they are allowed to create
This prevents accidental cluster-wide changes from a single misconfigured chart.
Observability for GitOps: what to monitor (not just apps)
Teams often monitor applications and forget to monitor the delivery control plane.
At minimum, treat these as first-class signals:
- Argo CD controller health and reconciliation latency
- Sync failure rates and top error reasons
- Kubernetes API error rates (often the real cause of “deployment is stuck”)
- Drift events and unexpected manual changes
Operationally, your on-call should be able to answer:
- Is Argo CD reconciling normally?
- Did the last deployment actually become healthy, or just “synced”?
- Did anything change in the cluster outside Git?
Common failure modes (and how to avoid them)
“Helm values drifted into a thousand overrides”
Fix by standardising:
- A small set of allowed overrides per environment
- Platform defaults in the chart
- A review checklist that rejects excessive templating and unbounded values sprawl
“Argo CD is installed, but teams still deploy with kubectl”
Fix by making GitOps the easiest path:
- Provide a service template (chart + app definition)
- Automate bootstrap for new services
- Make approvals fast (good PR templates, clear ownership)
“GitOps made us slower”
This happens when GitOps is introduced as a governance layer only.
Fix by pairing governance with enablement:
- Golden path charts
- Self-service namespaces
- Clear rollout patterns (standardised probes, standardised autoscaling)
A 30-day adoption plan you can execute
If you want momentum without regressions, aim for an incremental rollout.
Week 1: Foundation
Standardise:
- Repo strategy (split or mono)
- Environment promotion model
- Artefact versioning (image tags, chart versions)
Week 2: Helm packaging baseline
Deliver:
- One “reference chart” with good defaults
- Values structure for dev/staging/prod
- A CI pipeline that publishes images and charts
Week 3: Argo CD rollout
Deliver:
- Argo CD with SSO/RBAC appropriate to your org
- Projects for team boundaries
- A first service deployed end-to-end via GitOps
Week 4: Guardrails and reliability
Add:
- Policy-as-code and basic security controls
- Observability for Argo CD and deployment health
- A rollback drill (yes, actually rehearse it)
Where Tasrie IT Services can help
Teams typically ask for help when GitOps is “mostly working” but still fragile: unclear repo boundaries, Helm sprawl, inconsistent environment promotion, and risky production rollouts.
Tasrie IT Services supports engineering organisations with Kubernetes and DevOps delivery systems, including GitOps design, Helm standardisation, Argo CD implementation, and the operational guardrails (security, observability, and cost controls) that make the platform reliable at scale.
If you want to sanity-check your current approach, start with a short architecture review and map your deployment flow from commit to production, then identify the highest-risk handoffs and where GitOps can remove them.