Cloud native is no longer a niche strategy reserved for digital natives. In 2025 it is the default way high‑performing engineering teams design, ship, and operate software. Yet the term still gets blurred with containers or Kubernetes alone. This guide breaks down the fundamentals, the core patterns that matter, the common pitfalls to avoid, and the very real payoffs when you do it right.
What “cloud native” really means
The Cloud Native Computing Foundation defines cloud native as building and running scalable applications in dynamic environments using containers, service meshes, microservices, immutable infrastructure, and declarative APIs. The goal is speed and resilience through automation and loose coupling, not just moving to someone else’s data centre. See the CNCF’s definition for the full context here.
At a practical level, teams that succeed with cloud native tend to align on a few principles:
- Small, independently deployable services with clear contracts
- Everything as code, from infrastructure to policies and dashboards
- Immutable builds promoted through environments, not patched in place
- Declarative state, reconciled continuously by controllers (for example, Kubernetes)
- Shift‑left security and quality gates in the delivery pipeline
- Deep observability with metrics, logs, traces, and actionable SLOs
- A platform mindset that abstracts paved paths for developers
Most organisations now run Kubernetes in production and standardise on containers, according to CNCF annual surveys of end‑user adoption. The opportunity is no longer whether to adopt, but how to adopt without adding accidental complexity.
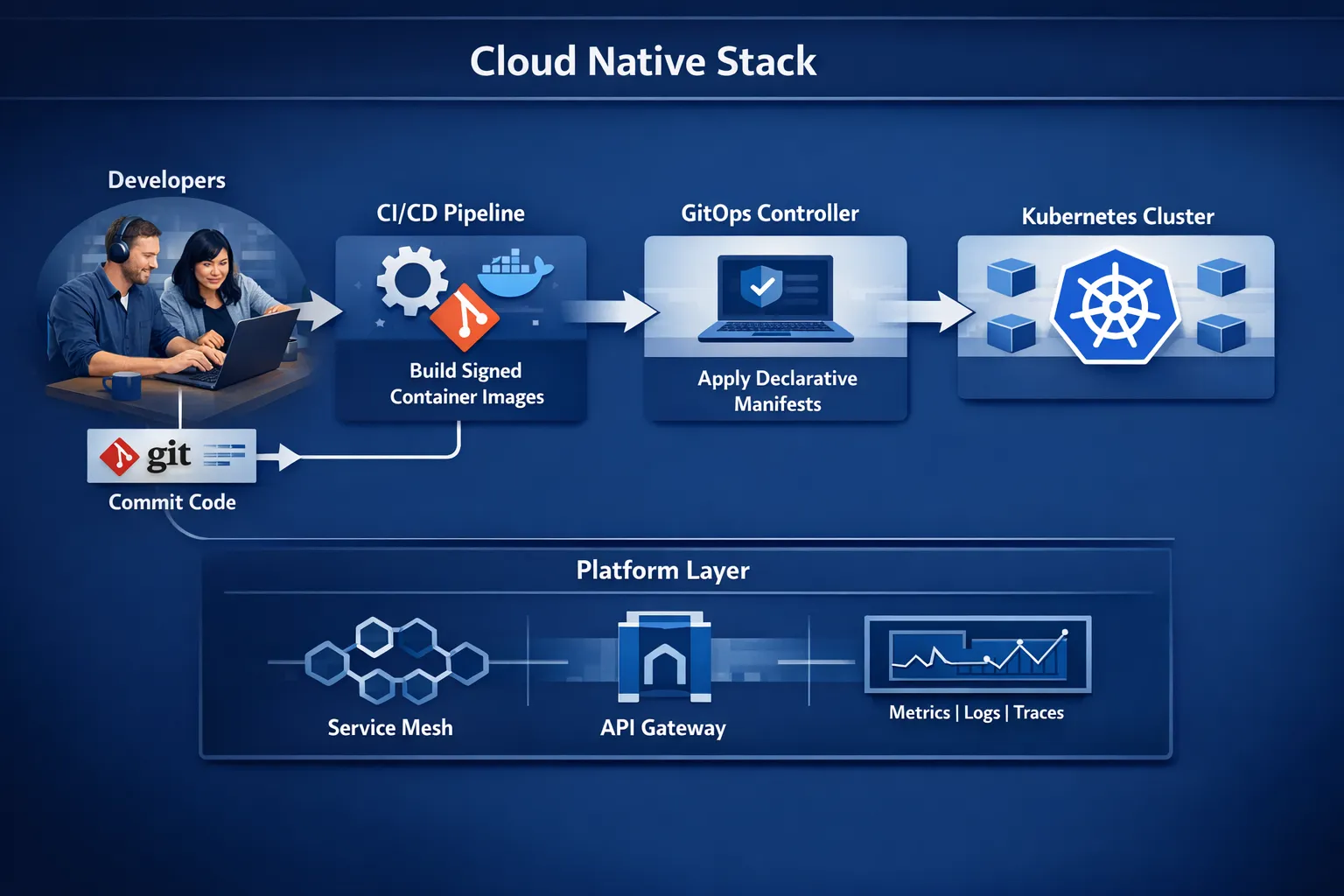
Core patterns you will use again and again
Patterns give a shared language for design trade‑offs. Below are the ones that repeatedly deliver value in modern platforms.
1) 12‑Factor and beyond
The Twelve‑Factor App remains a solid baseline for microservice design: explicit dependencies, config in the environment, stateless processes, disposability, and dev‑prod parity. It is worth revisiting as you factor monoliths into services. The original guide is concise and timeless at 12factor.net.
2) Containers with minimal, deterministic images
Keep images slim, pinned, and reproducible, and separate build and runtime stages. Embed SBOMs, sign images, and scan continuously. Deterministic builds shorten lead time and reduce vulnerability noise.
3) Orchestration and declarative reconciliation
Kubernetes popularised controllers that converge desired state to actual state. Lean into this model. Use Custom Resource Definitions for platform capabilities, and let controllers own day‑2 operations like rollouts, scaling, and recovery.
4) GitOps for consistent environments
Store desired state in Git, use pull requests for change, and let a controller sync clusters from Git rather than pushing from CI. This adds auditability and fast, safe rollbacks. For an in‑depth look at why teams migrate to this approach, see our guide on ArgoCD.
5) Sidecars and the service mesh
The sidecar pattern enriches a workload without modifying its code, for example for mTLS, retries, or telemetry. A service mesh introduces consistent policies for traffic, identity, and resilience across services. Use meshes where you need consistent security and traffic policy, not by default everywhere.
6) Resilience patterns
Retries with backoff, timeouts, bulkheads, circuit breakers, and idempotent handlers protect the system under stress. Bake these into platform libraries or mesh policy rather than re‑implementing in every service.
7) Event‑driven and at‑least‑once semantics
Events decouple producers and consumers and scale well. Embrace eventual consistency and design for duplicate handling. Managed streaming services like Amazon MSK can simplify operations; see our primer on AWS MSK.
8) Database‑per‑service, with careful state management
State is where cloud native ambitions meet physics. Prefer independent datastores per service, choose the right consistency model, and plan for backup, restore, schema evolution, and locality. Our overview of NoSQL vs MySQL and the CAP theorem can help frame choices.
9) Observability from day zero
Instrument every service with metrics, logs, and traces, ideally through OpenTelemetry to avoid lock‑in. Set SLOs and error budgets and wire alerts to user impact. Our guide to observability covers the tooling landscape and design choices.
10) Policy as code and paved paths
Apply guardrails with OPA/rego or cloud policy engines, enforce workload standards, and give developers composable templates for common use cases. The platform’s job is to make the right thing the easy thing.
Patterns, when to use them, and what to watch
| Pattern | Use when | Typical enablers | Trade‑offs |
|---|---|---|---|
| GitOps deployments | You want auditable, consistent cluster changes and quick rollbacks | Argo CD, Flux, signed manifests, branch protection | Requires discipline around repo structure and access control |
| Sidecar for cross‑cutting concerns | You need mTLS, telemetry, or retries without changing app code | Envoy, service mesh, OpenTelemetry collector | Extra hops and resources, operational complexity |
| Event‑driven integration | Services must decouple and scale independently | Kafka or Amazon MSK, schema registry, consumer groups | Eventual consistency, duplicate handling and ordering concerns |
| Stateless services with horizontal scaling | Traffic is bursty or global, you need elasticity | Kubernetes HPA/VPA, autoscaling groups | State moves to external stores and caches |
| Database per service | Teams need autonomy and independent scaling | Managed RDS, DynamoDB, MongoDB, Postgres | Cross‑service queries are harder, consistency boundaries matter |
| API gateway with zero‑trust policies | External or partner traffic must be secured and governed | API gateway, WAF, identity provider | Central point can become a bottleneck if poorly scaled |
None of these are silver bullets. The art is choosing the smallest set that solves real problems for your teams.
The pitfalls that slow teams down
Many cloud native initiatives stumble not on technology, but on operating model and discipline. These are the traps we see most often.
- Lift‑and‑shifting a monolith into a container without changing the delivery model. You get none of the elasticity or speed, only extra operational surface area.
- Recreating a bespoke platform for every team. Platform sprawl destroys reliability and inflates costs. Aim for a small, opinionated platform with extension points.
- Treating Kubernetes as a PaaS. It is a toolkit, not a complete product. Without CI/CD, GitOps, observability, policy, and cost controls, day‑2 will be painful. If you are starting on AWS, our walkthrough on using the Terraform EKS module shows how to build a solid baseline quickly.
- Ignoring supply chain security. Images without provenance, unpinned dependencies, and secrets in environment variables are common and avoidable. Sign images, verify at admission, and store secrets with strong encryption.
- Over‑optimising costs too early or too late. Early penny‑pinching slows delivery. Late cost control leads to surprise bills. Bake in cost visibility and right‑sizing from the start. Our guide to cloud performance tuning shares practical wins.
- Under‑investing in observability and SLOs. If you cannot see it, you cannot trust it. Instrument once, use everywhere, and align alerts to user journeys. See our observability primer for patterns and tools.
- Multi‑cloud by aspiration, not by requirement. Running the same stack across providers is one of the hardest engineering tasks. Only take it on if vendor risk or regulation demands it, and architect for the least common denominator.
- Forgetting data gravity. Latency to state kills performance. Place compute near data and plan data movement explicitly.
- No platform product owner. Someone must own the paved path, backlog, and developer experience. Without that, internal platforms drift and lose credibility.
- Tool selection by popularity rather than fit. Prefer boring, well‑supported tools that integrate cleanly and match team skills.
The payoffs when you get it right
Organisations that adopt cloud native fundamentals see consistent, measurable improvements. Research from the DORA programme continues to show that teams with mature DevOps and platform practices deploy more frequently, recover faster, and improve reliability. You do not need heroics to achieve this, only a consistent operating model.
Common payoffs include:
- Shorter lead time for changes, because builds and environments are deterministic and automated
- Higher deployment frequency, because each service is small and independently releasable
- Lower change failure rate, because tests, policies, and progressive delivery catch issues early
- Faster recovery, because rollbacks are safe and infra is declarative
- Cost transparency and better unit economics, because usage is tagged and right‑sized
- Stronger security posture, because supply chain controls and least privilege are enforced in code
A pragmatic adoption roadmap
You do not have to do everything at once. The following path works well across teams and industries.
Step 1: Baseline the platform
Stand up a minimal, production‑grade cluster with infrastructure as code, identity, networking, logging, metrics, and backups. Keep it simple and documented. On AWS, EKS plus Terraform gives a proven starting point, as shown in our EKS module guide.
Step 2: Ship one service the new way
Pick a low‑risk, high‑learning workload. Containerise it properly, add health checks, instrument with OpenTelemetry, and set an SLO. Build and sign the image in CI, deploy with GitOps, and measure the entire flow.
Step 3: Establish paved paths
Codify reusable templates for a web service, a job, and an event consumer. Include CI/CD, observability, security scanning, and runtime policy. Publish these as a developer portal or internal docs.
Step 4: Automate guardrails
Adopt policy as code for admission controls, set resource quotas and network policies, and enforce image provenance. Make the safe path the default.
Step 5: Expand service by service
Migrate more workloads, prioritising business value. Only introduce new components, for example a service mesh, when you have a clear policy or resilience need.
Step 6: Industrialise day‑2
Add autoscaling policies, cost visibility, chaos experiments, disaster recovery drills, and regular resilience reviews. This is where reliability and cost gains compound.
Measuring what matters
Tie cloud native progress to business outcomes. A simple scorecard keeps everyone aligned.
| Capability | Metric to track | Why it matters |
|---|---|---|
| Delivery | Deployment frequency, lead time for change | Shows speed and flow efficiency |
| Reliability | Change failure rate, time to restore, SLO compliance | Links engineering work to user experience |
| Cost | Cost per request or per tenant, idle to utilised ratio | Encourages design for efficiency, not just raw savings |
| Security | Mean time to remediate vulnerabilities, policy violations prevented | Validates supply chain and runtime controls |
| Observability | Trace coverage, alert noise ratio, dashboard adoption | Ensures issues are detected and actionable |
OpenTelemetry has become the de facto standard for vendor‑neutral telemetry, making it easier to collect signals once and route them to your tools of choice. Explore the project at opentelemetry.io. For broad industry benchmarks on delivery performance, the DORA State of DevOps research is the best starting point, available from Google Cloud here.
Cloud native on AWS, the common building blocks
Every organisation’s stack will differ, but the following building blocks appear frequently on AWS:
- EKS for orchestration, with managed node groups for simplicity
- Terraform for infrastructure as code and reproducibility
- ECR for image storage with scanning and lifecycle policies
- Argo CD or Flux for GitOps deployments
- Prometheus and Grafana for metrics and dashboards, with CloudWatch as a central sink
- OpenTelemetry for traces and vendor‑neutral data collection
- AWS MSK for streaming and event‑driven integrations
- Secrets Manager or SOPS for secret management
- An API gateway plus a WAF for safe ingress
If you are exploring migration paths and toolchains, our overview of cloud migration tools can help frame the planning stage.

How Tasrie IT Services can help
Tasrie IT Services specialises in DevOps, cloud native and Kubernetes consulting, CI/CD automation, infrastructure as code, security, observability, AWS managed services, and data analytics. We meet teams where they are, and focus on measurable outcomes:
- Platform assessments that benchmark your current delivery, reliability, and cost posture
- Hands‑on enablement to establish GitOps, IaC, and observability foundations
- Kubernetes design, provisioning, and operations aligned to your governance model
- CI/CD pipelines with policy gates, image signing, and automated rollbacks
- Monitoring and SLO design that ties engineering work to user experience
- Pragmatic cost optimisation woven into your platform, not bolted on later
If you want to accelerate cloud native adoption without the common detours, speak to our team. Explore our services at Tasrie IT Services or dive into related topics on our blog, including Kubernetes vs Docker, Observability, and Why migrate to ArgoCD.
Key takeaways
- Cloud native is a set of operating principles, not just containers or Kubernetes
- A small set of patterns, for example GitOps, sidecars, resilience, and observability, delivers most of the value
- Avoid common traps like platform sprawl, weak supply chain controls, and skipping SLOs
- Measure progress with DORA metrics, SLOs, and cost per unit, then improve iteratively
- Start small, establish paved paths, automate guardrails, and scale deliberately
The payoffs are real, from faster delivery to higher reliability and clearer unit economics. With the right patterns and a pragmatic roadmap, your teams can realise them sooner rather than later.