Modern cloud engineering is no longer about just spinning up instances. High‑scale teams must deliver rapid changes without sacrificing reliability, security, or cost control. The strongest teams align around clear outcomes, paved‑road tooling, and disciplined operations that make doing the right thing the easiest thing. This guide collects practical, field‑tested best practices for engineering leaders and platform teams building and running at scale.
Start with outcomes, not tools
Before discussing stacks and patterns, align on measurable outcomes and how you will track them. The most widely adopted delivery metrics come from the DORA research programme, which focuses on deployment frequency, lead time for changes, change failure rate, and time to restore service. Elite performers consistently excel on these measures, and there is strong evidence that improving them correlates with better organisational performance. See the latest findings from DORA for definitions and guidance.
For reliability, define service level objectives and error budgets so you can balance release velocity with stability. The approach is documented in Google’s SRE practices, which remain a gold standard for operating at scale. The freely available Site Reliability Engineering book is an excellent reference.
For cost, define unit economics that make sense for your business, for example cost per 1,000 requests, cost per order, or cost per active user, and track them alongside DORA and SLOs. The FinOps Framework offers practical disciplines for cloud cost management.
Design teams for flow and ownership
Technology choices only pay off when team structures enable fast, safe delivery.
- Create a platform engineering team that provides golden paths, reusable modules, and self‑service tooling. Their job is to reduce cognitive load for product teams and standardise the boring but important parts like networking, security controls, and CI pipeline templates.
- Keep product teams end‑to‑end accountable, from code to production telemetry. Avoid split responsibilities that cause hand‑offs and waiting.
- Publish clear service ownership, escalation paths, and on‑call rotations. Shared services are owned like products, with a roadmap and SLOs.
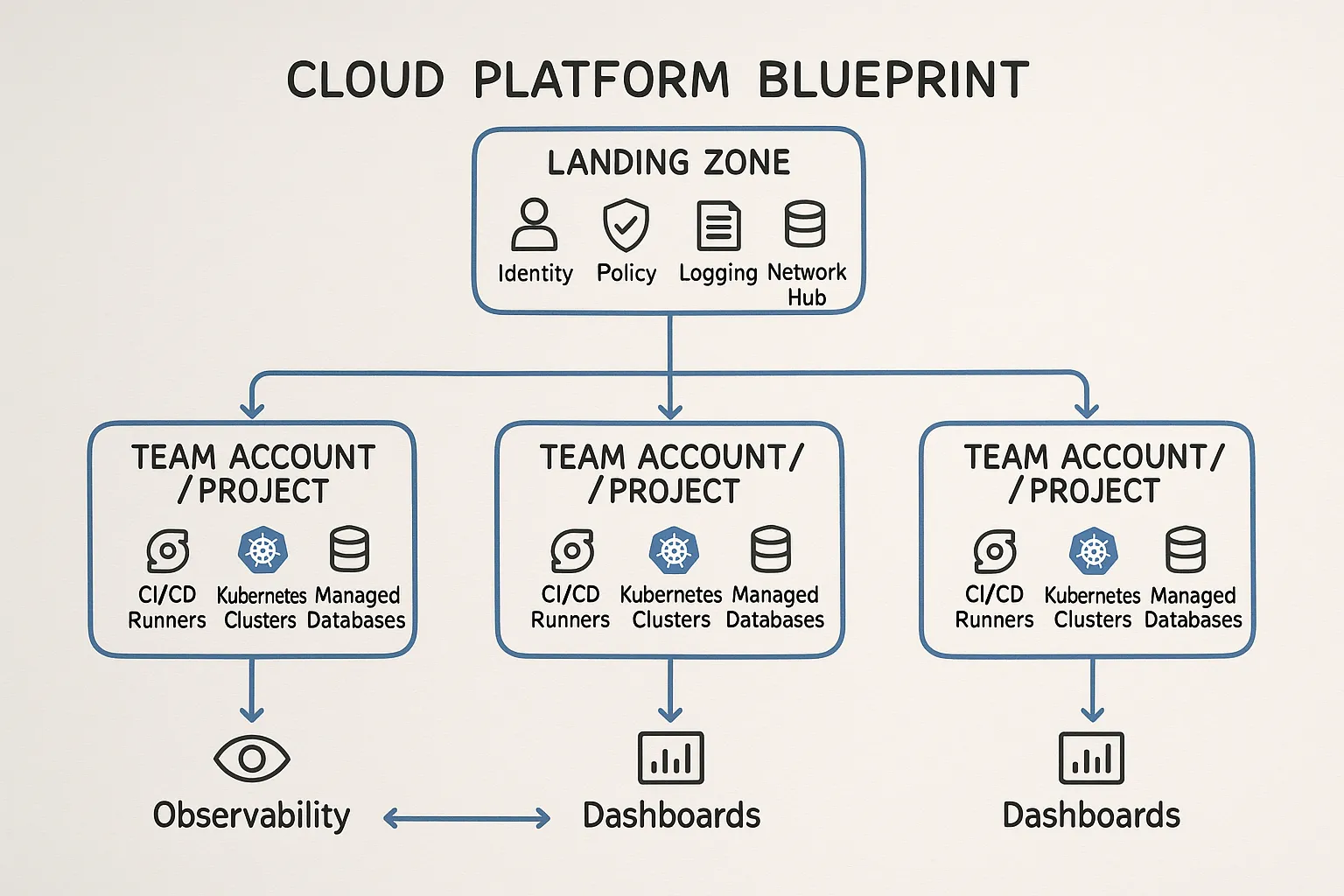
Establish a secure landing zone and multi‑account strategy
At scale, isolation and guardrails matter more than any individual service feature.
- Use a multi‑account or multi‑project model for strong isolation between environments and teams. Centralise identity and guardrails, decentralise delivery.
- Adopt a landing zone that standardises identity, network baselines, logging, encryption, and guardrails from day one. On AWS, for example, organisations often build on Control Tower and IAM Identity Center to enforce this pattern. See the AWS Well‑Architected Framework for design reviews.
- Separate production from non‑production networking and blast radius. Use a hub and spoke network with centralised egress controls and VPC peering or transit gateways.
- Encrypt everything at rest and in transit. Back this with key management policies, automatic key rotation, and envelope encryption for sensitive workloads.
Build everything with Infrastructure as Code and GitOps
Consistency beats heroics at scale. Treat infrastructure as product code.
- Use Terraform to define cloud resources and create a standard module library with sensible defaults, tagging policy, encryption, and monitoring baked in. If you are operating on Kubernetes, manage manifests declaratively with Kustomize or Helm.
- Manage configuration and deployments with GitOps so that the live state matches what is declared in version control. Tools like Argo CD support drift detection and pull request based changes. If you are evaluating GitOps on Kubernetes, see our guide on why migrate to Argo CD.
- Apply policy as code with admission controls and OPA or equivalent. Enforce allowed regions, instance types, tagging, and network rules in CI and at deployment time.
- Use automated plan, apply, and promotion gates in CI. No manual changes to long‑lived environments. Keep secrets outside repos and rotate them regularly.
If you are provisioning Kubernetes on AWS, our tutorial on the Terraform EKS module shows a production‑grade starting point.
Standardise CI/CD for hundreds of services
A consistent, fast pipeline is a force multiplier for high‑scale teams.
- Prefer trunk‑based development with small pull requests, automated tests, and fast feedback. This supports the DORA metrics and reduces merge pain.
- Create reusable pipeline templates, one per language or framework, with steps for linting, SAST, unit tests, dependency checks, SBOM generation, container build, vulnerability scan, and provenance attestation. For Kubernetes, enable progressive delivery strategies like canary and blue‑green.
- Enable ephemeral preview environments for pull requests where practical. They improve review quality and reduce surprises at release time.
- Separate continuous integration from continuous delivery. CD should be driven by GitOps or a release controller that applies policies and SLO‑aware release gates.
If you are weighing container orchestration approaches, our overview of Kubernetes vs Docker may help clarify the roles of each layer.
Engineer for reliability with SLOs and capacity planning
Reliability is an engineering discipline, not a hope.
- Define SLIs that reflect user experience, for example availability of a critical endpoint, 99th percentile latency, or streaming lag. Set SLOs per service and track error budgets.
- Use load testing and capacity modelling early, then feed results into autoscaling policies. Right‑size instance families and database capacity with automated observability signals.
- Plan for failure. Use multi‑AZ by default, evaluate multi‑region or active‑active where the business case supports it. Practice disaster recovery and game days.
- Keep rollbacks simple and rehearsed. Immutable deployments, versioned artefacts, and fast restore procedures save hours during incidents.
For a pragmatic deep dive on tuning, see our guide to cloud performance optimisation.
Make observability a product capability
You cannot fix what you cannot see. Observability must be uniform and automated.
- Ship logs, metrics, and traces for every service with consistent correlation identifiers. Capture golden signals like latency, traffic, errors, and saturation.
- Provide a standardised dashboard per service and a platform‑level view. Include SLO burn rates and release markers so engineering and product can reason together.
- Adopt tracing for distributed systems and event pipelines. It dramatically reduces mean time to recovery by showing where time is spent.
- Add profiling and real user monitoring for performance‑sensitive apps. Retain enough history for trend analysis and anomaly detection.
Read our overview of observability fundamentals for a structured approach and tool options.
Shift security left and enforce it continuously
Security scales when it is default and automated.
- Identity and access management first. Centralised identity, least privilege, short‑lived credentials, and automated role provisioning. Prefer workload identity over long‑lived keys.
- Supply chain security in CI. Scan dependencies, containers, and infrastructure plans. Generate SBOMs and attestations, and store them with artefacts. The SLSA framework offers a maturity model for build integrity.
- Encrypt secrets with a managed vault, rotate regularly, and avoid environment sprawl. Lock down egress and adopt zero trust network principles per NIST SP 800‑207.
- Continuously validate posture with policy as code and drift detection. Aggregate findings in a central security hub and route alerts with runbook links.
Build event‑driven and data‑aware systems
As scale grows, data shape and timeliness become first‑class concerns.
- Choose the right storage for the workload. For transactional systems, a relational database with well‑tuned indexes and read replicas. For high‑throughput time series or analytics, consider columnar or specialised datastores. Our primers on NoSQL vs MySQL and the CAP theorem explain these trade‑offs.
- Standardise data contracts. Use schema registries for streaming, version schemas carefully, and validate compatibility in CI. On AWS, Amazon MSK integrates well with Glue Schema Registry. See our introduction to AWS MSK for patterns and setup.
- Treat pipelines as code with tests and observability. Measure data freshness, volume, and quality. Alert on schema drift and late data.
Practise FinOps and unit cost control
Cost is an engineering constraint like latency or error rate. Put it in the feedback loop.
- Tag everything by service, environment, and owner. Enforce tagging in CI and policy tools so showback and chargeback are reliable.
- Build cost dashboards that map to units that matter to the business. Investigate anomalies quickly, and perform regular rightsizing and savings plan reviews.
- Estimate the cost impact of architectural decisions, for example cross‑region data transfer or chatty microservices, before you commit to them.
- Include cost tests in CI for infrastructure changes. Fail a pull request if a plan exceeds a predefined budget threshold.
The FinOps Framework provides concrete practices for scaling this discipline across teams.
Run incidents well and learn from them
Incidents are inevitable, how you respond and learn is optional.
- Define severity levels, roles, and communication channels. Keep incident rooms small, with clear command and scribe roles.
- Use runbooks with copy‑paste commands and expected outcomes. Link them directly from alerts and dashboards.
- Conduct blameless post‑incident reviews that produce concrete actions, owners, and deadlines. Track action completion and share learnings widely.
If you operate Kubernetes, ensure responders know how to quickly inspect pods and logs. Our quick guide to kubectl logs can help streamline triage.
A pragmatic 90‑day blueprint
- Days 1 to 30, establish outcomes and guardrails. Define DORA metrics and SLOs, set up a secure landing zone with multi‑account isolation, centralised logging, and baseline policies. Choose and publish golden path pipeline templates.
- Days 31 to 60, codify infrastructure and delivery. Create Terraform modules and GitOps controllers, onboard two pilot services end‑to‑end, and implement unit cost dashboards with enforced tagging.
- Days 61 to 90, scale and harden. Roll out standard observability and SLO dashboards to top services, rehearse a disaster recovery scenario, enable progressive delivery, and complete your first blameless post‑incident reviews with tracked actions.
Quick reference, best practice to outcome map
| Best practice | What it enables | How to measure |
|---|---|---|
| Multi‑account landing zone with policy guardrails | Strong isolation and safer autonomy | Fewer high‑impact incidents, time to provision new account |
| Terraform modules and GitOps | Consistent, auditable change | Change failure rate, drift count to zero |
| Trunk‑based development with reusable CI templates | Faster, safer delivery | Lead time for changes, deployment frequency |
| SLOs and error budgets | Balanced speed and reliability | SLO attainment, burn rate |
| Standard observability with tracing | Faster diagnosis, better performance | MTTR, p95 latency, trace coverage |
| Shift‑left security and SBOMs | Reduced exposure and faster fixes | Vulnerability mean time to remediate, policy violations per change |
| Unit cost dashboards and enforced tagging | Cost transparency and optimisation | Cost per business unit, anomaly detection mean time to respond |
Common pitfalls to avoid
- Custom snowflake environments that bypass the platform team. The cost of variation compounds linearly with the number of teams.
- Over‑centralisation that blocks delivery. Provide guardrails and self‑service, not ticket queues.
- Under‑investing in testing and release strategies. Canary and feature flags are cheaper than rollbacks.
- Tool proliferation without standards. Curate a small set of well supported tools and templates.
- Observability as an afterthought. Retrofitting telemetry is costly and incomplete.
Further reading and references
- DORA Accelerate, research and resources
- Site Reliability Engineering, Google
- AWS Well‑Architected Framework
- OpenGitOps principles, CNCF
- NIST SP 800‑207, Zero Trust Architecture
- SLSA, Supply-chain Levels for Software Artifacts
FAQs
What is the difference between cloud engineering and DevOps? Cloud engineering focuses on designing, building, and operating cloud platforms and services. DevOps is a set of cultural and technical practices that bring development and operations together. In practice they overlap, and high‑scale teams combine both with platform engineering.
How do we know if we are ready for GitOps? If your infrastructure and application manifests are declarative and you can apply changes through automation, you are ready to trial GitOps on a non‑critical service. Aim for drift detection, pull request based changes, and auditable rollbacks. Our guide on migrating to Argo CD explains the benefits and approach.
Do we need Kubernetes for high‑scale systems? Not always. Kubernetes shines for large fleets of services with demanding reliability and runtime control. For simpler needs, managed platform services or serverless can be faster to market. See Kubernetes vs Docker for context.
How should we budget for multi‑region? Treat it as a product decision. Multi‑region can improve availability and latency but increases complexity and cost. Model the expected SLO gain and compare it to added spend and operational burden.
What are the first signals to instrument in a new service? Latency, traffic, error rate, and saturation. Add distributed tracing from day one and define at least one SLO that reflects user experience. Our observability guide covers this in detail.
How do we keep costs under control as teams scale? Enforce tagging, publish unit costs, and integrate cost checks into CI for infrastructure changes. Review savings plans and rightsizing monthly. Our article on cloud performance tuning includes practical tactics.
How Tasrie IT Services can help
Tasrie IT Services partners with engineering leaders to operationalise these best practices, from secure landing zones and platform engineering to GitOps, Kubernetes, observability, and FinOps. If you want senior experts to accelerate your cloud engineering roadmap and deliver measurable outcomes, get in touch at Tasrie IT Services.